We’ve all heard the phrase, “Anything that can go wrong, will go wrong”…otherwise known as Murphy’s Law. I couldn’t find a better phrase to describe a recent problem we encountered at AIS Managed Services.
We’ve all heard the phrase, “Anything that can go wrong, will go wrong”…otherwise known as Murphy’s Law. I couldn’t find a better phrase to describe a recent problem we encountered at AIS Managed Services.
I’ve been a part of the Managed Services practice at AIS for quite some time now. As part of this practice, we provide proactive and reactive support to various clients. Internally, we support the AIS Internet site and the AIS Blog, as well as multiple enterprise-level commercial and federal customers. This blog post covers the challenges of availability monitoring, related to a downtime incident right here on the AIS Blog.
The Problem…
The AIS Blog an important Azure-hosted asset to AIS, so we have configured availability monitoring through Azure’s Application Insights. This is supplemented with external monitoring through Site24x7’s tools.
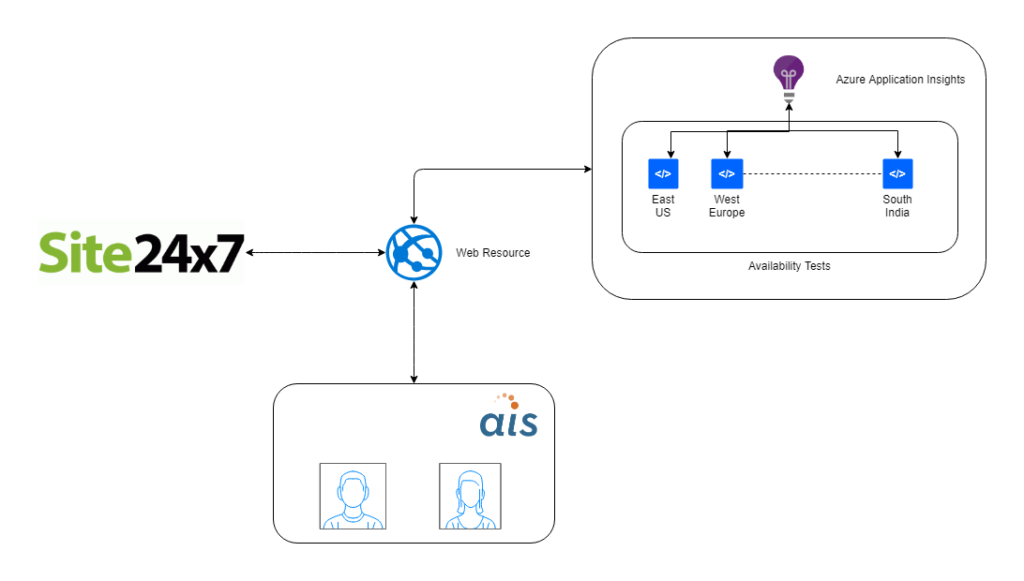 One fine day, we got an alert from Site24x7 that our blog site was unreachable. We checked and indeed it was down…but surprisingly, we didn’t receive any alert from Azure’s Availability tests. These availability tests check the blog site availability from five different locations around the world every five minutes, around the clock. The Application Insights instance running these availability tests is hosted in the East U.S. region.
One fine day, we got an alert from Site24x7 that our blog site was unreachable. We checked and indeed it was down…but surprisingly, we didn’t receive any alert from Azure’s Availability tests. These availability tests check the blog site availability from five different locations around the world every five minutes, around the clock. The Application Insights instance running these availability tests is hosted in the East U.S. region.
We didn’t receive any email alerts from the Azure Application Insights availability tests until two hours had passed, by which time we had already resolved the downtime incident. We also checked for any Azure-related notice that could describe an issue affecting the availability tests or the Application Insights instance.
What the Azure Team Told Us…
We contacted the Azure team about this abnormal behavior of Availability tests. We were notified that there was an issue in the underlying Azure Fabric dealing with the Storage. Because the underlying storage was down, the Application Insights instance in its entirety failed for a duration of almost two hours. Once the storage was back up, we received the alerts regarding site being down.
Lessons Learned…
Intuitively, we already knew that availability monitoring should be done externally in case of a situation like this (thus the redundant Site24x7 Availability monitors and alerts), but we were interested in exactly why Application Insights Availability tests were affected in this situation. So, we asked several other questions to the Azure team regarding Application Insights and we learned the following lessons:
- Never trust a single vendor for monitoring itself. We were only made aware of this downtime event because we also had alerts from an external monitoring tool and we were not completely reliant on Application Insights, which had its own coinciding downtime event.
- Even if you have multiple locations configured in the availability tests, if the specific region hosting your Application Insights instance (in our case it was East U.S.) is experiencing issues, the ping checks will not work.
- Having multiple monitoring services (especially with telemetry logging) is not recommended by Microsoft as they can create conflicts with Application Insights and you might even face invalid telemetry loggings.
At Managed Services, we strive towards perfection, so our proactive and reactive support offerings include periodic automated and manual checks. We aim to have zero percent downtime from and in case of any downtime related to a third party, we triage the incident promptly and ensure that we are satisfied by the root cause analysis before sharing with our customers.
Please visit the AIS Managed Services site or contact sales@aisteam for more information on our Managed Service offerings.