Recently, I was involved in a project where we had requirements. A report needed to be built based on data from several sources, including Azure Cosmos DB and Azure SQL. This report was required to be stored in Azure, and data was subject to a retention policy where it would be unable to be deleted. For this use case, we decided to use Azure Data Factory to read the data, transform the data, and load the data into a CSV file within a blob container in an Azure Storage Account. Then, to prevent the deletion of data, we would create a retention policy on the blob container to enable immutable storage, giving us write-once, read-many capabilities.
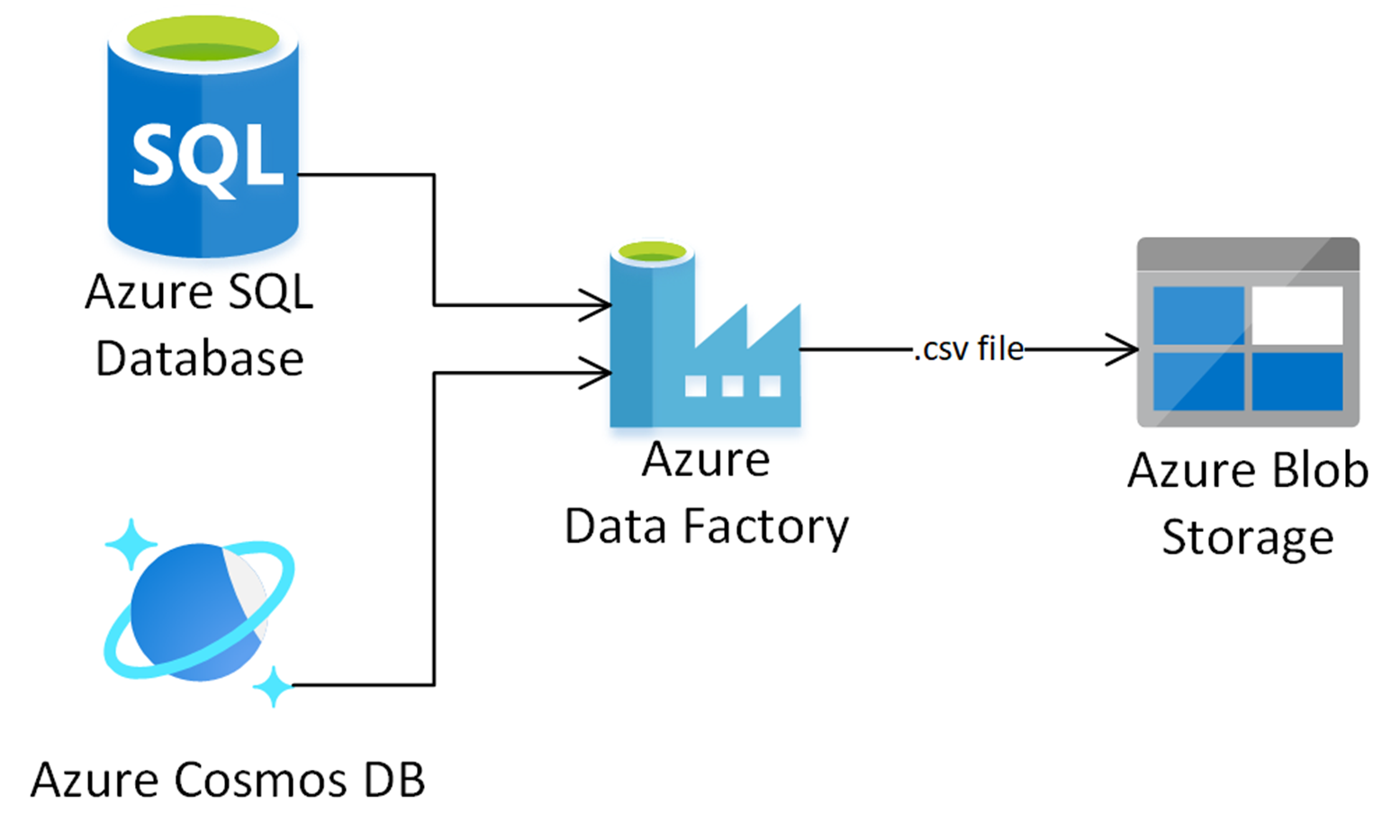
We found that we needed a Data Flow within Azure Data Factory to perform logic such as joining across our data sources. We created an output sink to a Delimited Text output within an Azure Blob Storage Linked Service within our data flow.
Immutable storage policies divided into retention policies and legal holds can be enabled on a storage account to enforce write-once, read-many policies, which allow new documents to be added to the storage account. But, it prevents the modification and deletion of existing documents. In the case of a retention policy, individual blobs cannot be modified or deleted until the retention period has passed for a given blob. In the case of legal holds, no blobs can be modified or deleted until the legal hold is manually removed from the blob container. Legal holds can be used to fulfill various legal requirements, including keeping data under active investigation from being modified. You can read more about immutable storage in the official Microsoft documentation for Immutable storage for blobs.
Our project had legal requirements for retaining these created documents, so we found immutable storage policies to be a good fit. When we enabled Immutable Storage, either through a retention policy or a legal hold on the Blob Container, we encountered one of two errors:
Job failed due to reason: Spark job failed in one of the cluster nodes while writing data in one partition to sink, with following error message: This operation is not permitted as the blob is immutable due to a policy.
OR
Job failed due to reason: Spark job failed in one of the cluster nodes while writing data in one partition to sink, with the following error message: This operation is not permitted as the blob is immutable due to one or more legal holds.
Here, we will examine why this error occurs, and how we can resolve these errors.
Setup
To simplify our example, I will create a simple Azure Data Factory pipeline that uses a data flow to read from an Azure SQL server, performs a Select operation on that data, and then output a CSV file into an Azure Storage Blob Container.
I created an Azure SQL server to hold our source data. This server has a database named testdb, and a table named MOCK_DATA with a few columns of varying data types. I then inserted some mock data into the table.
SERVICE OFFERING: REHOST ON AZURE
Initiate your cloud journey on Microsoft technologies to accelerate your cloud transformation. Learn more about the benefits of rehosting.
I then created an Azure Storage Account to hold our final data, with a blob container named “output.” This is where I will store the final CSV files output by the Azure Data Factory.
To make these blobs immutable, I added a legal hold to the output container:
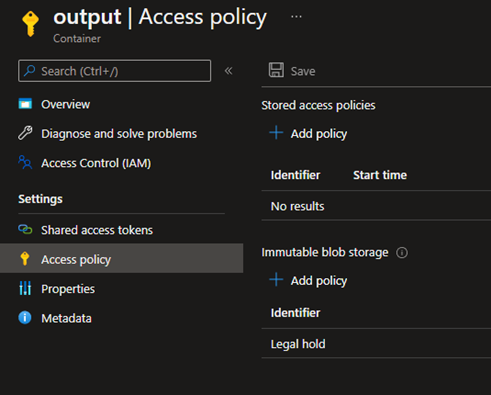
I then created a new Azure Data Factory:
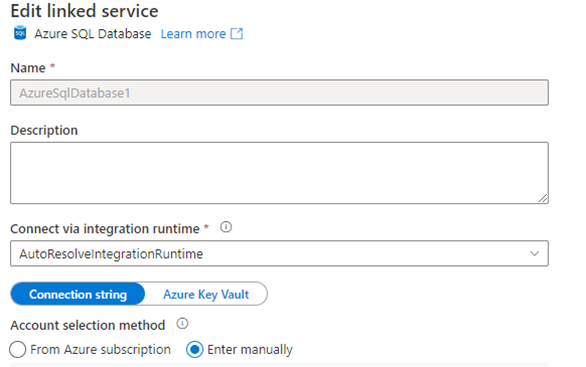
Opening Azure Data Factory Studio, I created the following. A new Linked Service, associated with my Azure SQL Server:
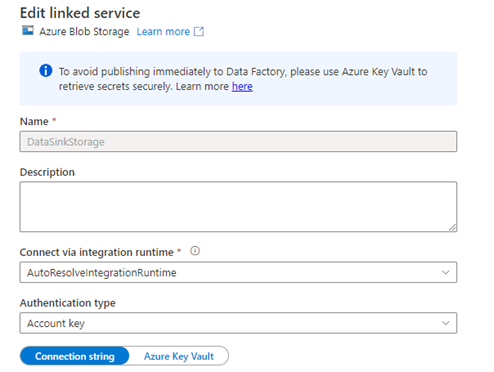
A second Linked Service, associated with Azure Blob Storage:
An Azure SQL Database Dataset, with the linked service associated to my SQL Database and the table source associated with my mock data table:
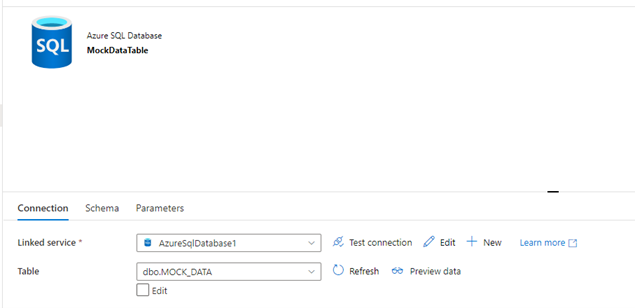
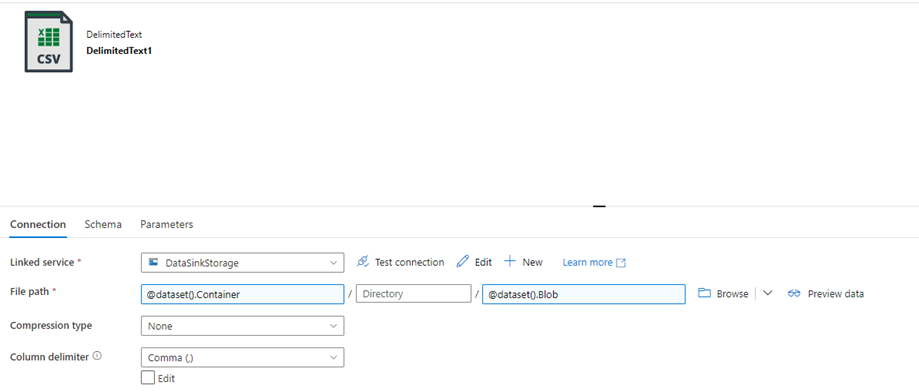
An Azure Blob Storage Delimited Text Dataset, associated with my Blob Storage Linked Service, and with two parameters, Container and Blob, that are associated with the File path:
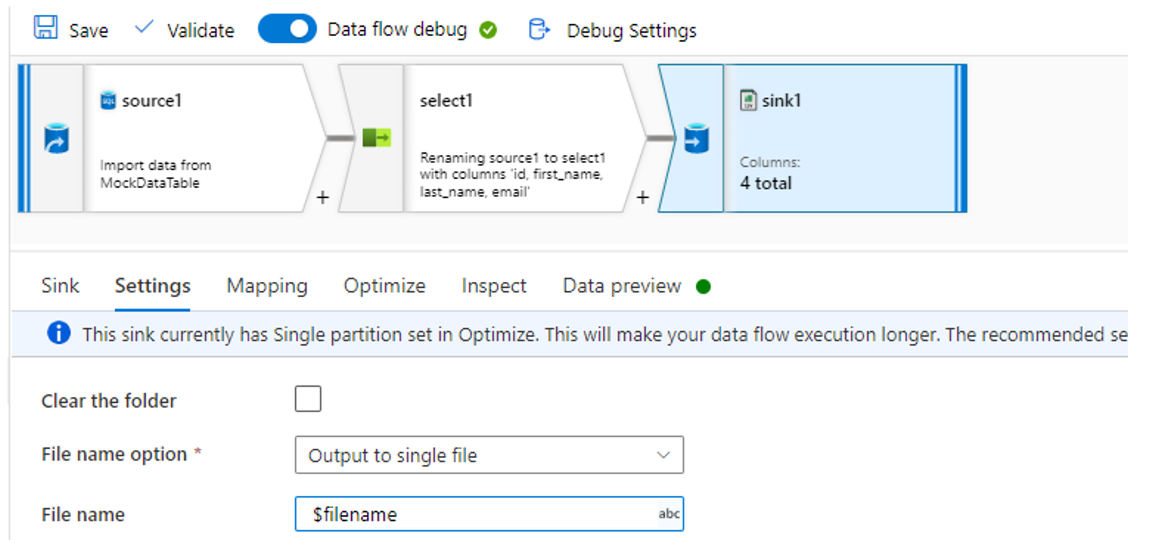
A Dataflow, which has the following configuration:
- A parameter named filename
- A Source associated with the mock data table dataset, with all default options.
- A Select activity to simulate processing the data to select specific columns
- A Sink activity with the following settings:
- Dataset: The delimited text dataset
- Settings tab:
- File name option: Output to a single file
- File name: $filename
- Optimize: Single partition
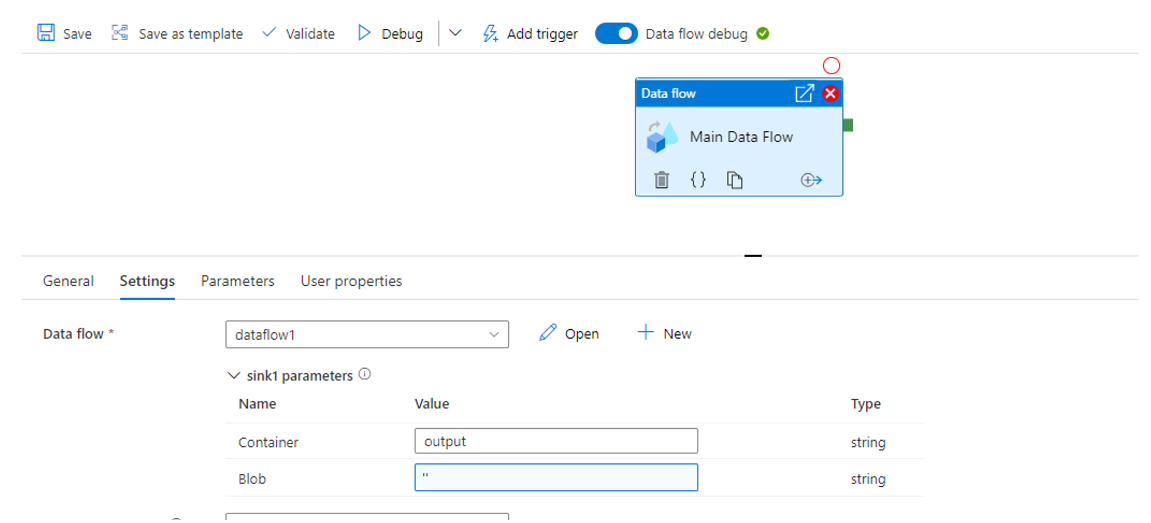
A Pipeline with a Data Flow activity, associated with the Data Flow that was just built, with the following parameters:
- Sink parameters:
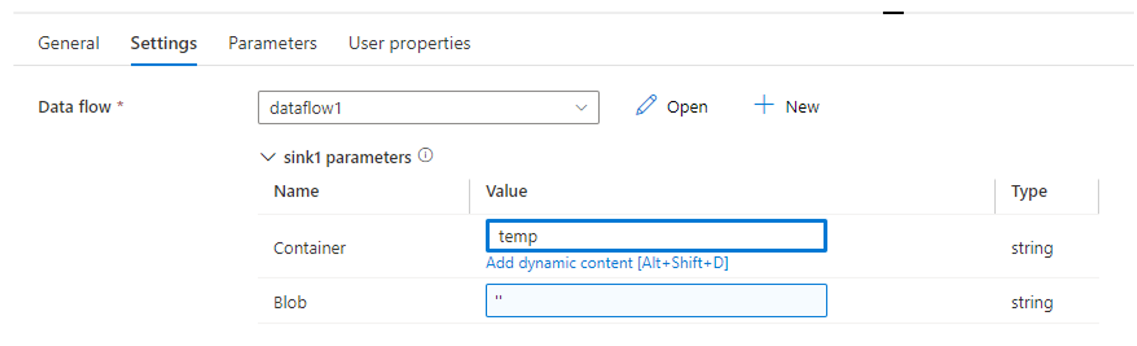
- Container: output
- Blob: A dynamic content value with an empty string, ”
- Other parameters:
- filename: Data flow expression, “file1.csv”
When I run this pipeline, I get the following error:
Job failed due to reason: Spark job failed in one of the cluster nodes while writing data in one partition to sink, with the following error message: This operation is not permitted as the blob is immutable due to one or more legal holds.
Solution
Why do we get an error when running this pipeline? When the Spark data cluster associated with the Data Flow activity runs, it creates several temporary files within the Blob Container. It then attempts to append to these files and delete them after processing.

This violates the write-once, read-many restrictions on the storage blob container so that the Data Factory job will fail.
To resolve this issue, I will need to create a temporary location for these files to be built and then copy that data from one storage account to another. First, I will create a new blob storage container with no retention restrictions, which I will call “temp”:
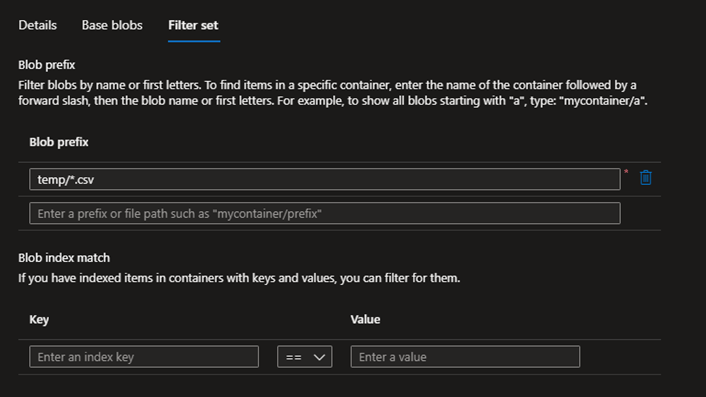
Then, on the storage account, to clean up the temporary data, I will enable lifecycle management. I created a new lifecycle management rule on the storage account to delete old files by providing the following settings:
- Rule scope: Limit blobs with filters
- Blob type: Block blobs
- Blob subtype: Base blobs
- Base blobs rules:
- Add a rule: If base blobs haven’t been modified in 1 day, then delete the blobs
- Filter set:
- Blob prefix: temp/*.csv

Next, back in Azure Data Factory, in my pipeline, I changed the dataflow sink parameters to use the temp blob container rather than the output blob container:
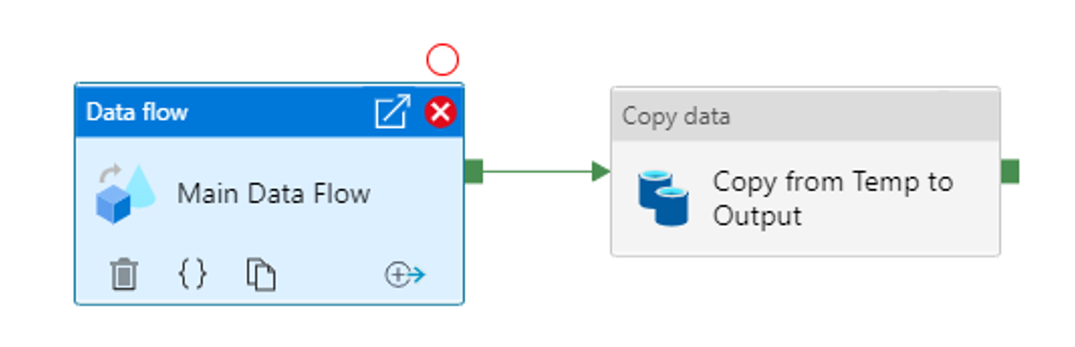
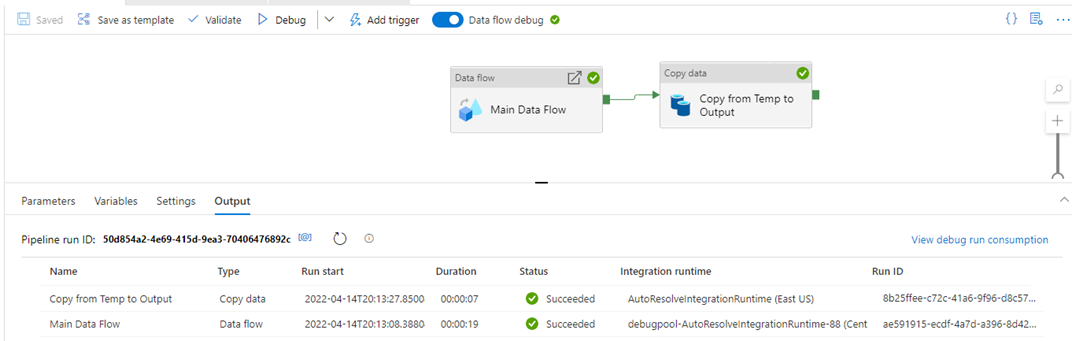
The Copy Data activity does not work the same way as a Data Flow sink and does not create temporary files in its process. I created a new Copy Data activity in the pipeline, and attached the data flow’s anchor to the copy data activity:
For the Source of the Copy Data activity, I selected the Delimited Text dataset and provided the following settings:
- Container: temp
- Blob: file1.csv
For the Sink of the Copy Data activity, I selected the same Delimited Text dataset and provided the following settings:
- Container: output
- Blob: file1.csv
Rerun the pipeline. The pipeline should run successfully, and your output file will exist in both the temp and output blob containers. After our lifecycle management policies find that the temporary blob is over a day old, the temporary blob will be deleted, while the output blob will remain. The retention policy will prevent the output blob from being deleted.
Summary
The way the Data Flow activity in Azure Data Factory uses temporary files to build delimited text outputs, using a delimited text output as a Data Sink is not possible on an Azure Storage Blob Container with an immutable storage policy. A temporary storage output destination must exist as the output for the data flow, which is then copied over to the final, firm storage destination with a Copy Data activity to work around this restriction. The Copy Data activity is not processed the same way as the Data Flow sink. It does not create temporary files, so it is suitable for copying data from the temporary container to the output container. The temporary container is then cleaned regularly by creating a lifecycle management policy on the storage account.