AIS is working with a large organization that wants to discover relationships between data and the business by iteratively integrating data from many sources into Azure Data Lake. The data will be analyzed by different groups within the organization to discover new factors that might affect the business. Data will then be published to the appropriate consumers using PowerBI.
In the initial phase, data lake ingests data from some of the Operational Systems. Eventually, data will be captured not only from all the organization’s systems but also from streaming data from IoT devices.
Azure Data Lake
Azure Data Lake allows us to store a vast amount of data of various types and structures. Data can be analyzed and transformed by Data Scientists and Data Engineers.
The challenge with any data lake system is preventing it from becoming a data swamp. To establish an inventory of what is in a data lake, we capture the metadata such as origin, size, and content type during ingestion. We also have the Interface Control Document (ICD) from the Operational Systems that describe the data definition of the source data.
Logical Zones
The data in the data lake is segregated into logical zones to allow logical and physical separation to keep the environment secure, organized and agile. As the data progress through the zones various transformation is performed.
- Landing Zone is a place where the original data files are stored untouched. No data is deleted from this zone, and access to this zone is limited.
- Raw Zone is a place where data quality validation is applied based on the rules defined in source ICD. Any data filed validation moves to Error Zone.
- Curated Zone is a place where we store the cleansed and transformed data and ready for consumption. The transformation is done for different audiences, and within the Zone, folders will be created for each specialized change.
- Error Zone is a place where we store data that filed validation. A notification is sent to the registered data curators upon arriving new data.
- Metadata Zone is a place where we keep track of metadata of the source and the transformed data.
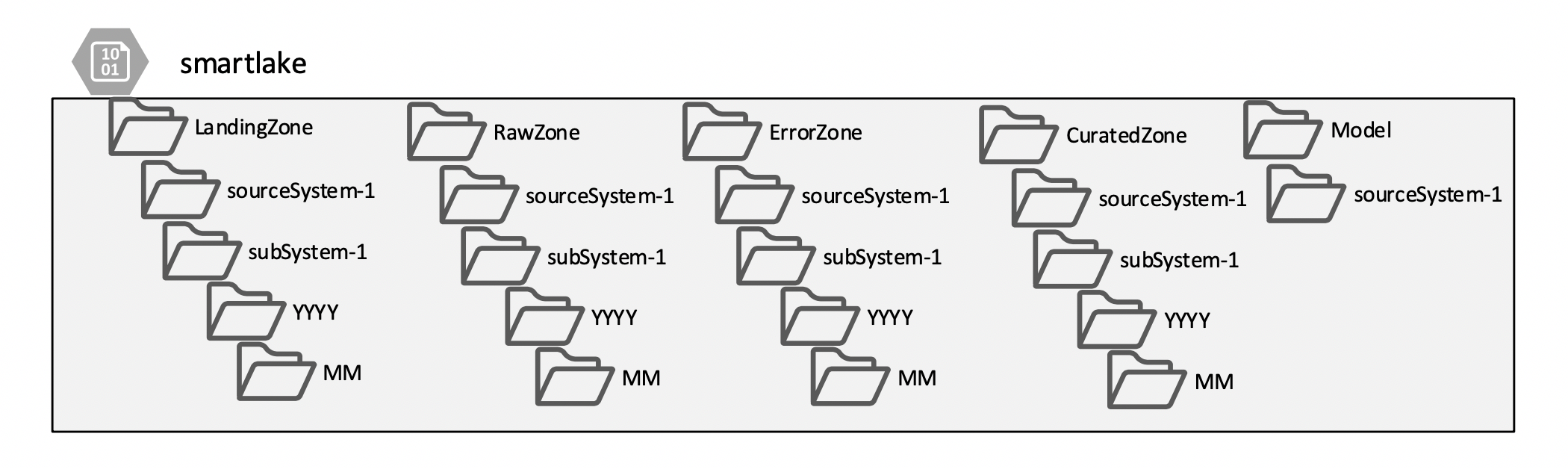
The source systems have security requirements that prevent access to sensitive data. When the folders are created, permissions are given to security groups in Azure Active Directory. The same security rules are applied to the subsequent folders.
Now that the data is in the data lake, we allow each consuming group to create their own transformation rules. The transformed data is then moved to the curated zone ready to be loaded to the Azure Data Warehouse.
Azure Data Factory
Azure Data Factory orchestrated the movement and transformation of data, as shown in the diagram below. When a file is dropped in the Landing Zone, the Azure Data Factory pipeline that consists of activities to Unzip, Validate, Transform, and Load the data into Data Warehouse.
The unzipping is performed by a custom code Azure Function activity rather than the copy activity’s decompress functionality. The out of box functionality of Azure Data Factory can be used to uncompressed only GZip, Deflate and BZip2 files but not Tar, Rar, 7Zip, Lzip.
The basic validation rules, such as data range, valid values, and reference data, are described in the ICD. A custom Azure Function activity was created to validate the incoming data.
Data is transformed using Spark activity in Azure Data Factory for each consuming user. Each consumer has a folder under the Curated Zone.
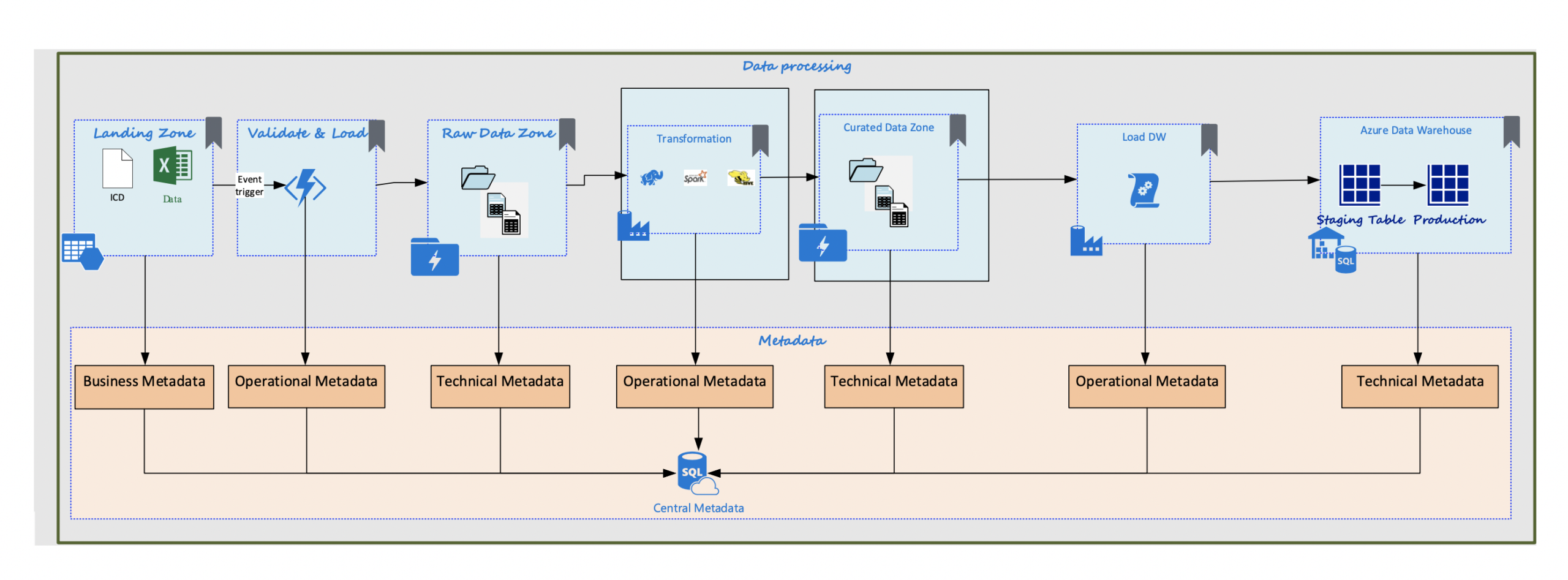
Tables in the Azure Data Warehouse were created based on the Curated zone by executing the Generate Azure Function activity to create data definition language (DDL). The script modifies the destination table if there is a new field added.
Finally, the data is copied to the destination tables to be used by end-users and warehouse designers.
In each step, we captured business, operational, and technical metadata to help us descript the data in the lake. The metadata information can be uploaded to a metadata management system in the future.