 Azure Redis Cache Geo-Replication gives you the ability to link two Redis caches across Azure regions, thus establishing a primary/secondary relationship across the regions. So is this capability best-suited for Disaster Recovery (DR), High Availability (HA) or both? Let’s investigate.
Azure Redis Cache Geo-Replication gives you the ability to link two Redis caches across Azure regions, thus establishing a primary/secondary relationship across the regions. So is this capability best-suited for Disaster Recovery (DR), High Availability (HA) or both? Let’s investigate.
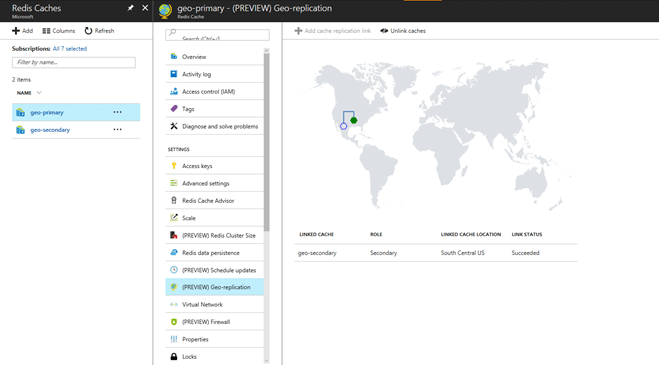
Once you have set up Azure caches in two regions (let’s assume for this discussion that the East region is primary and West is secondary), you can establish a link between via the portal. (Note that a Command Line Interface [CLI] to establish the link is not yet available). Once the link is established, the secondary cluster becomes read-only.
During the normal course of events, all writes in the East region will be instantaneously (albeit asynchronously) sent to the West region. In this way, the West-based Redis cache is pretty much current with writes in the East region (minus any transactions that may be in flight). This delta between primary and secondary caches will depend on a number of factors, including load on the primary cache, bandwidth available on the cache machine, inter-region latency etc.
If we ever need to fail-over to the West region for any reason, we would need to do the following:
- Manually delete the geo link. This will make the West Cluster read/write. Automatic fail-over is not yet supported.
- Change the connection string to West region-based cache, which in our case will be part of the fail-over anyway.
- Manually setup *another* geo-replication link (*if* failback – i.e. ability to return to the East region if required). However, at this point a full sync would need to take place back to the East region cache. How much time would it take to conduct a full sync? The Microsoft team suggests that the replication time for a full 53 GB geo-replicated pair in East U.S. and West U.S. regions can be anywhere between five to 10 minutes.
Finally, note that the Redis Geo-Replication features does not offer a RPO. In fact, import/export and persistence are disabled for caches in replicated mode.
In conclusion, the lack of a CLI for setting up the replication link and the manual failover requirements suggest that, at the time of writing this blog post, geo-replication capability is designed primarily for DR and not HA.