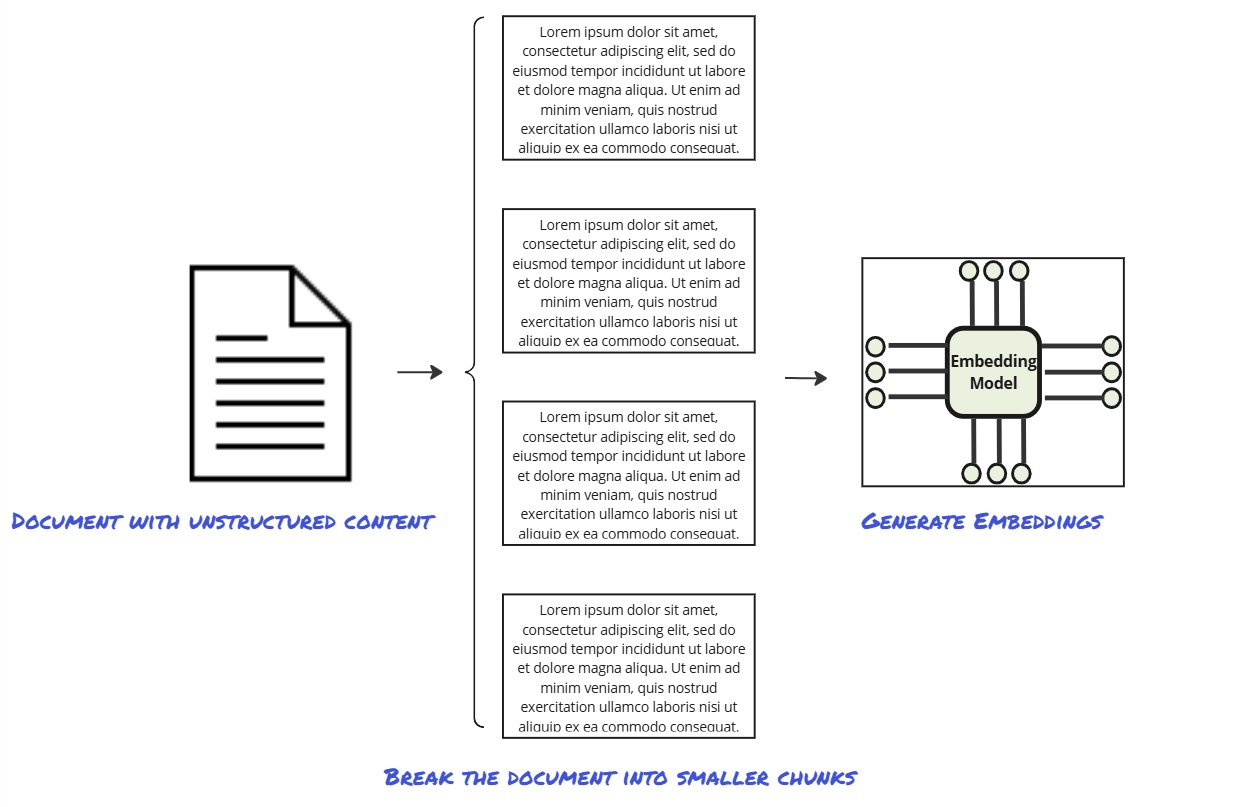
Transforming raw information into content that machines can process effectively is a critical function as unstructured data continues to grow exponentially in today’s workplaces. At its core, content chunking is the process of breaking down large pieces of information into smaller, manageable segments (“chunks”) while preserving the right amount of context.
In this post, we will explore strategies for chunking content to maximize the effectiveness of generative AI systems in domain-specific scenarios. We will examine how these methods can enhance a model’s understanding and retrieval accuracy. We will also highlight how knowledge workers can play a role in refining effective chunking processes by structuring content, identifying key semantic breaks, and validating outputs to ensure accuracy and context.
Why Content Chunking Matters
The relationship between chunking and embeddings
Embeddings are numerical representations of data that capture this data’s semantic meaning – the meaning beyond the literal words. These embeddings enable AI models to process, compare, and retrieve information efficiently – they are at the heart of effective generative AI systems. But before unstructured content can be transformed into embeddings, it often must be broken down into smaller, manageable units through chunking.
And the quality of your content chunking approach directly impacts the quality of your embeddings. If chunks are too “coarse” they may lose the ability to accurately represent a specific concept or run up against the token limits (which could cause the embedding model to miss key details).. On the other hand, overly small chunks may fail to capture the right context and lead to embeddings that lack the true meaning of the content beyond the literal words. Striking the right balance in chunk size is important for these reasons.
In addition, content chunking helps address the variability of unstructured data. Documents, emails, and data of other formats often include sections of varying length and importance. By intelligently dividing content into chunks – through fixed-length methods or context-aware techniques depending on the scenario – effective chunking helps maximize the chances that each segment is meaningful. These embeddings then become the foundation for semantic search and retrieval by our generative AI systems.
Challenges working with large unstructured data
Generative AI systems can face challenges when working with large, unstructured data. These challenges stem from technical constraints, such as token limits, as well as complexities inherent in the data itself.
- Token Limits: Generative AI systems typically have a maximum number of tokens they can process in a single inference request. Exceeding these limits can result in truncation, where information is cut off, leading to incomplete or inaccurate results. This can be challenging in unstructured documents like reports, where essential context might appear later in the text but is inaccessible to the model. Token limits consider the compute and infrastructure required to process a given request (making the practical token limit different from a model’s supported context window).
- Loss of Context Across Chunks: Breaking long data into smaller chunks can disrupt semantic relationships between sections. For example, separating related paragraphs or splitting a sentence mid-way can result in embeddings that fail to capture the full meaning, reducing the quality of downstream AI tasks like retrieval or summarization.
- Varying Content Structures: Unstructured documents frequently contain a range of different formats; text, tables, charts, bullet points, images, etc. These different formats require thoughtful chunking strategies. For instance, chunking a table row-by-row may work well for numerical analysis but could limit the understanding of relationships between rows on retrieval.
- Metadata and Annotations: Many unstructured datasets include valuable metadata or annotations, such as timestamps, authorship details, or highlighted content. Properly associating these with their corresponding text chunks can be helpful in maintaining context.
- Duplicate and Redundant Information: Unstructured data often contains overlapping or repetitive information, such as recurring phrases in email threads or multiple versions of a document. Without careful handling, embeddings may be generated that confuse retrieval processes and waste resources.
- Noise and Irrelevant Information: Unstructured text often includes noise, such as legal disclaimers, formatting artifacts, or typographical errors. If these elements are not filtered out during preprocessing, they can generate embeddings that detract from the accuracy and relevance of AI outputs.
- Dynamic Content Updates: In environments where data is frequently updated, maintaining alignment between chunks, embeddings, and the latest content versions is a challenge. Stale embeddings can lead to inaccurate retrieval, and reprocessing entire datasets can strain systems.
Content Chunking Strategies
Fixed-Length Chunking
Fixed-length chunking is a straightforward method of dividing text into equal-sized segments based on characters, words, or tokens. This approach mostly disregards the semantic content of the text, focusing instead on creating uniform chunks that are easy to process. For instance, a document might be split into chunks of five hundred tokens each, regardless of sentence or paragraph boundaries. Fixed-length chunking is commonly used in scenarios where data is relatively simple.
- Advantage: Its simplicity makes it easy to implement, and the uniform chunk size aligns well with the token limits of embedding models. Fixed-length chunking also scales effectively, making it good for processing large datasets or streaming data quickly. By eliminating the need for complex boundary-detection algorithms, fixed-length chunking minimizes preprocessing overhead.
- Disadvantage: However, the limitations of fixed-length chunking are notable. By splitting text arbitrarily, it often disrupts semantic relationships. Valuable information that spans chunk boundaries may be lost or duplicated, which can reduce the quality of retrieval. Additionally, this method is inflexible, struggling with documents that contain diverse content formats such as tables or images. While fixed-length chunking is efficient and scalable, it may require supplementary techniques, like overlapping chunks to address these shortcomings.
Example 1: Consider processing a large corpus of news articles for topic modeling (high-level trends). Splitting each article into 500-token chunks allows the system to uniformly encode text for embeddings without worrying about preserving the narrative flow of individual pieces. Since the task focuses on high-level trends or themes rather than detailed semantics, the uniformity and efficiency of fixed-length chunking may outweigh the need for precise contextual integrity.
Example 2: For a quick negative example, imagine a research paper discussing advancements in AI, with the following sentence:
“AI models have significantly improved diagnostic accuracy. In clinical trials, these systems demonstrated an 18% reduction in misdiagnoses compared to traditional methods.”
Using fixed-length chunking, this text might be split arbitrarily, resulting in one chunk ending with:
“AI models have significantly improved diagnostic…”
and the next beginning with:
“…accuracy. In clinical trials, these systems demonstrated…”
This split disrupts the semantic flow, making it harder for an AI model to capture the context that ties the diagnostic improvement to clinical trials. Consequently, the embeddings generated for each chunk may lose critical meaning, reducing the effectiveness of downstream retrieval or generation tasks.
Dynamic or Context-Aware Chunking
Dynamic or context-aware chunking goes beyond fixed-size segmentation by splitting text based on its semantic structure and natural language boundaries. This approach identifies meaningful points to divide content, such as sentence breaks, paragraph transitions, or logical sections, ensuring that each chunk maintains contextual integrity. A report may be chunked by complete sections rather than arbitrary lengths, preserving relationships between sentences. Tools like spaCy, NLTK, and Hugging Face Transformers are commonly used for implementing dynamic chunking, as they can identify linguistic patterns and adapt to the complexity of unstructured data.
- Advantage: The key advantage of dynamic chunking lies in its ability to preserve semantic meaning, which improves the quality of embeddings and the accuracy of downstream tasks like retrieval and summarization. By producing coherent chunks, dynamic chunking enables generative AI systems to create more meaningful embeddings, leading to higher retrieval precision.
- Disadvantage: This method requires additional preprocessing time and computational resources, making it more complex and slower than fixed-length chunking when processing large datasets or real-time applications.
Example: One example of where context-aware chunking may be ideal is in processing legal contracts, where maintaining semantic integrity is critical. Splitting a contract arbitrarily could separate legal clauses that depend on one another, such as a liability clause and its corresponding exceptions. By dynamically chunking the text at natural boundaries like section headers or punctuation, each chunk retains complete, meaningful clauses. This helps the related embeddings capture the full legal context, enabling precise retrieval of relevant sections during tasks like contract review or compliance analysis.
Hierarchical Chunking
Hierarchical chunking is a structured method for dividing text into layered segments, combining fixed-length and context-aware strategies to retain both high-level and granular context. This approach breaks documents into larger sections, such as chapters or major headings, and further segments these into smaller, more manageable chunks like paragraphs or sentences. For example, a research report could be divided by chapters using context-aware segmentation and then split into smaller fixed-length chunks within each chapter. This layered method ensures that both broad overviews and fine-grained details are preserved, making it ideal for complex documents that require nuanced processing.
- Advantage: The primary advantage of hierarchical chunking lies in its flexibility and ability to support multiple levels of context. By combining the strengths of fixed-length and dynamic chunking, it adapts to varied content types and maintains semantic integrity across layers. This approach enables precise embeddings that capture different levels of meaning which improves retrieval accuracy for diverse queries (whether a user needs a high-level summary or specific details).
- Disadvantage: Hierarchical chunking introduces complexity in implementation, requiring sophisticated tools or rules to segment text at multiple levels. It also demands additional computational resources to store and process embeddings for both broad and granular chunks. Moreover, this method depends on the document having clear structural elements, such as headings or logical divisions, which may require preprocessing in unstructured datasets. Despite these challenges, hierarchical chunking’s ability to balance high-level structure and detailed granularity makes it a powerful tool for managing and vectorizing large, complex datasets.
Example: Imagine a 200-page technical manual for a complex device, such as an industrial 3D printer. The manual is structured into major sections, including “Installation Guide,” “Maintenance,” and “Troubleshooting.” Each section contains subsections, such as “Hardware Setup” or “Error Codes,” and within those, detailed instructions, diagrams, and explanations.
Using hierarchical chunking, the manual would first be segmented by chapters (context-aware segmentation), preserving the broad context of each major section. For example, the “Troubleshooting” section would form one high-level chunk. Then, within “Troubleshooting,” subsections like “Error Codes” would become intermediate chunks, each capturing related errors and their resolutions. Finally, these subsections would be further divided into smaller, fixed-length or sentence-based chunks, where each chunk corresponds to a specific error code and its detailed explanation. Let’s say a user asks, “How do I resolve error code E101?” With hierarchical chunking, the retrieval system first identifies the “Troubleshooting” chapter as relevant, then narrows down to the “Error Codes” subsection, and finally retrieves the chunk containing the E101 error details.
This multi-level approach ensures that the system provides precise, context-rich information. At the same time, if another user queries, “What are common troubleshooting steps for this printer?” the system could use higher-level chunks to return an overview from the “Troubleshooting” chapter without diving into unnecessary detail.
Multi-Modal Chunking
Multi-modal chunking addresses the challenge of processing documents that combine text with other formats, such as images, tables, and diagrams. This approach integrates diverse data types into cohesive chunks, ensuring that embeddings capture the full context of the document. For example, a technical report might include a table of specifications, a descriptive paragraph, and an accompanying diagram. Multi-modal chunking treats these elements as a single unit, preserving their relationships and providing a richer, more holistic representation of the content for AI processing.
- Advantage: The primary advantage of multi-modal chunking lies in its ability to improve retrieval accuracy and user experience. By embedding text and non-textual elements together, AI systems can respond more effectively to complex queries that require understanding of both narrative and visual data. For instance, a query about machine performance can return not only textual descriptions but also relevant graphs and charts. This approach supports a wide range of use cases, from medical diagnostics that combine imaging with notes to financial analysis integrating charts with textual explanations. However, multi-modal chunking requires sophisticated tools for extracting and embedding non-textual elements, such as OCR for images, table parsers like Tabula or Camelot, and models like CLIP for linking text with visual data.
- Disadvantage: Despite its advantages, multi-modal chunking introduces complexity and higher computational demands. Extracting, processing, and embedding diverse formats require more resources and depend heavily on the quality of the tools used. Poorly processed images or tables can degrade embedding accuracy, while the lack of standardization for multi-modal embeddings can make integration across systems more difficult. Nevertheless, for workflows where rich, contextual understanding is essential, multi-modal chunking provides a powerful solution to integrate and leverage diverse document elements effectively.
Example: Imagine a medical case study that documents a patient’s diagnostic journey. The document includes the following elements:
- Text-Based Diagnostic Notes: A narrative describing the patient’s symptoms, physical exam findings, and preliminary observations. “The patient presented with persistent lower back pain radiating to the left leg, accompanied by numbness in the left foot.”
- MRI Imaging: An accompanying MRI scan showing a herniated disc at the L4-L5 level, highlighted with annotations.
- Test Results in a Table: A summary of diagnostic test results, including blood work and imaging metrics.
Using multi-modal chunking, these elements are grouped together into a single unit or embedding. Instead of treating each component independently, multi-modal chunking preserves the relationships between them.
- The text describing lower back pain is linked to the table showing elevated inflammatory markers (ESR and CRP) and the annotated MRI scan of the herniated disc.
- Together, these elements create a rich, interconnected chunk that represents the patient’s condition holistically.
When a clinician queries the system with a prompt like, “What are the diagnostic findings for lower back pain with left-sided numbness?”, the generative AI system retrieves this multi-modal chunk. The response includes the MRI scan, an explanation of its findings, and the associated diagnostic notes and test results. This ensures the query is answered with a comprehensive and contextually rich response, rather than fragmented pieces of information.
How Knowledge Workers Can Assist with Content Chunking
Content Structure
Knowledge workers play an important role in preparing content for chunking by doing all they can to ensure documents are well-organized and easy for generative AI systems to process. Content structuring involves organizing information into a clear and logical format, with headings, bullet points, and distinct sections that reflect the document’s underlying meaning and intent. Well-structured documents make it easier to identify natural boundaries for chunking and therefore improve the quality of embeddings, as each chunk is more likely to capture complete and coherent semantic information.
Providing Context
Knowledge workers who are domain experts can also play a significant role in guiding the chunking process by ensuring that critical semantic boundaries within documents are preserved. While tools may exist that can recognize general language patterns like sentences or paragraphs, they may lack the nuanced understanding needed to manage specialized language in fields like law, medicine, or engineering. Knowledge workers with domain expertise bridge this gap by identifying key phrases, clauses, or content structures that must remain intact during chunking. This ensures that embeddings capture the full meaning of the content, improving the quality of tasks like retrieval and summarization.
In fields such as law, medicine, or technical documentation, certain elements require careful handling to retain their context. A few examples:
- Legal documents often contain key clauses like “force majeure” or “notwithstanding the foregoing” that define essential conditions and must not be split.
- Similarly, medical notes may describe symptoms tied directly to diagnoses, such as “persistent headache and blurred vision, indicative of intracranial hypertension” which would lose their diagnostic relevance if fragmented.
- Technical documents, like engineering specifications, frequently include parameters linked to measurements, such as “operates at 120 volts with a tolerance of ±10%”, which must remain together to maintain their utility.
Validating Chunk Outputs
Validating chunk outputs is an essential step in the chunking process, where knowledge workers review the segmented text to ensure it preserves meaning and context. While tools can efficiently generate chunks, they may produce fragments that disrupt semantic integrity, such as splitting sentences or combining unrelated sections. Knowledge workers bring a human perspective to this process, identifying and addressing such errors to maintain the quality of embeddings and the effectiveness of downstream AI tasks like retrieval or summarization.
During validation, knowledge workers focus on checking for fragmented context, boundary errors, and semantic coherence. For instance:
- A chunk that splits the sentence “The system failed due to overheating, causing operational delays” into separate segments obscures the causal relationship and reduces its utility.
- Similarly, in multi-modal documents, they ensure that visual elements like charts or tables remain correctly associated with their explanatory text. This review process ensures that each chunk represents a complete and meaningful unit.
Collaborating with Data Teams
Knowledge workers play a vital role as the bridge between data teams and end-users, straddling technical expertise and real-world application. In the context of refining chunking strategies, their domain knowledge and familiarity with end-user needs provide valuable insights that help data teams optimize the chunking process for specific use cases.
A key aspect of this collaboration is translating domain-specific requirements into technical specifications. Knowledge workers can articulate the importance of preserving critical semantic relationships within specialized content, such as linking clauses in legal documents or symptoms with diagnoses in medical records. Their input helps data teams design chunking strategies and storage strategies that respect these nuances. This feedback loop ensures that chunking strategies align with the content’s inherent structure and the needs of the end-users.
Conclusion
Chunking is a foundational step in transforming unstructured data into meaningful and manageable units for AI processing. By breaking down content into coherent chunks, organizations can enhance semantic understanding, improve retrieval accuracy, and optimize computational efficiency. However, not all chunking methods are created equal—different strategies, from fixed-length to hierarchical and multi-modal chunking, are better suited to specific contexts. Selecting the right approach depends on the nature of the data and the goals of the AI system.
Knowledge workers play an important role in implementing more complex, nuanced chunking strategies effectively. Their domain expertise helps preserve semantic relationships, validate chunk outputs, and bridge the gap between technical teams and end-users. Whether ensuring a contract clause remains intact or identifying the most meaningful way to chunk multi-modal content, knowledge workers provide the human insight needed to refine generative AI processes and align them with organizational needs.