






Embeddings have become a foundation of modern generative AI models, transforming how machines understand and generate human language. At their core, embeddings are a way to represent the meaning of words or entities (sentences, paragraphs, or entire documents) as ordered lists of numbers called vectors. These vectors capture linguistic properties as numerical values that, when examined in combination, help machines understand the semantic meaning and context of a word or series of words. More recently, embeddings have been applied to store the meaning of other kinds of data: images, video, audio, etc. This is one of the key enabling innovations for “multi-modal” AI.
Why it’s Important to Understand Embeddings
This innovation offers a powerful tool for knowledge workers. Embeddings allow us to represent the meaning of our content numerically, allowing AI models to understand and process our information with depth and accuracy. Embeddings are not just technical details; they represent a shift in how we can handle and leverage our data.
One of the most practical applications of embeddings for knowledge workers is in information retrieval. Embeddings enhance traditional search techniques by enabling more effective semantic search, where the AI model can understand the context and intent behind search queries. This means more efficient and accurate information retrieval, saving time and improving productivity. For instance, when combining embeddings with traditional keyword-based search methods, you can find relevant documents or data points that might have been missed.
Embeddings form the foundation of data processing in generative AI models, fundamental to how these models interpret and act on our input. Think of embeddings as the way AI “sees” our world. Embeddings bridge the gap between our unstructured information and complicated AI systems.
Demystifying Embeddings
Let’s take a look at a simple illustrative example of embeddings. Consider the following strings of text:
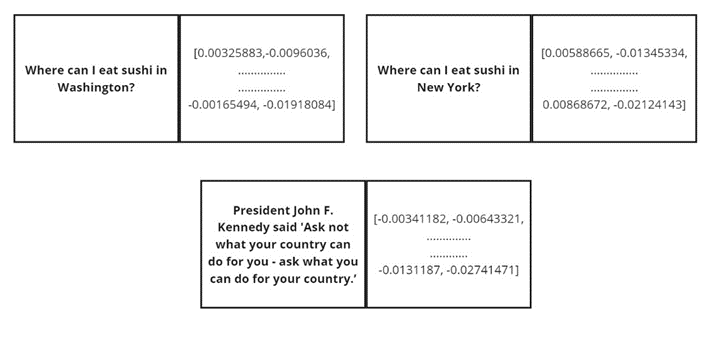
- “Where can I eat sushi in Washington?”
- “Where can I eat sushi in New York?”
- “President John F. Kennedy said, ‘Ask not what your country can do for you – ask what you can do for your country.’”
We’ll send each string of text through an API call to a model that will “translate” each string into a corresponding embedding—a series (vector) of floating-point numbers. For this example, we’ll use the broadly adopted (though now not the leading edge) “text-embedding-ada-002” model from OpenAI.

The image above is a summary of what’s returned from the model. For each string of text, we get back a series of 1,536 floating-point numbers. The size of the vector is based on the embedding model I’ve chosen; different models will produce vectors of varying sizes. These numbers are the “embedded” representation of each string of text. Again, the embedding is the contextual meaning of the chunk of text, captured numerically. In the image above, we’ve simplified the first and last two floating point numbers in each embedding.
Even with the incomplete representation of each embedding above, you can begin to understand what’s happening. First, take a look at the first numbers in each set directly below the strings of text related to eating sushi. Although they mean little to us in isolation, they seem to be relatively close when we compare the values. While there is a difference relating to a word at the end of the text (location; Washington -> New York), each string asks a question relating to eating sushi; the meaning of each string of text is similar.

Now, look at the last string and the accompanying embedding that was produced. This string of text is significantly different in meaning. If we look at the first number in this associated embedding, we can start to see – even in this first number – that what is represented in this embedding is significantly different.

It turns out that this is a convenient example in that the first number in each embedding illustrates the point well, but this won’t always be the case. You won’t be able to consistently rely on the fact that the first number alone will indicate a difference in the meaning of various pieces of text. However, if we were to analyze the set of all 1,536 floating point numbers in each embedding, the embeddings associated to the first two strings of text would be more closely related across all points than the third. And this fact is what makes embeddings useful in knowledge retrieval scenarios.
Embeddings and Knowledge Retrieval
Imagine that we want to make our chunks of text available to knowledge workers efficiently.For example, they may want to use a search system to find relevant content using a natural language query. Let’s build on our simple example to understand how embeddings can be used to help achieve this goal. Keep in mind that modern search systems and generative AI platforms that use embeddings for knowledge retrieval will take care of many of these details – we’re just providing a peek into what’s happening behind the scenes. We’ll use the simple strings of text and embeddings referenced above to illustrate.
As a starting point, let’s say the knowledge worker wants to issue a simple request, “Show me famous presidential quotes.” Now, our contrived example will tell us intuitively that the text referencing JFK’s famous quote will be the most relevant text to help answer the request. But how does a generative AI or search system get to the same conclusion? Generally, the process follows the following steps:
- Create an embedding for the input request
- Compare the input embedding with previously stored embeddings, measuring the similarity in terms of mathematical distance between each stored embedding and the input embedding.
- Rank the results based on the similarity score of each embedding.
- Return one or more of the results based on a threshold or preference. For example, you may want to return only the top one most correlated result, or you may choose to rank and return a larger number of chunks of text.
Let’s assume we’ve stored our previous embeddings in an accessible place that can be referenced directly. The embeddings themselves are not all that useful on their own, so we’ll also need to assume we’ve stored at least a pointer to the original text we can produce in a response. Think of this structure conceptually as a set of key-value pairs:
Following the process, we’ll create an embedding for the text “Show me famous presidential quotes.” It’s important to note that the model we use to make this embedding needs to be the same model used to create the stored embeddings, as each model takes a slightly different approach and returns vectors with varying dimensions as its output. We don’t need to store this input embedding outside of the context of this session:

Now, we can generate a “similarity score” to the input embedding for each of our stored embeddings. Typically, this similarity score is calculated using either a cosine similarity function or an Euclidean distance function. The approach choice is outside of this discussion’s scope, but cosine similarity is typically the more common approach. When we run a cosine similarity function against each embedding in our set, I get the following results:

The red arrow represents our input embedding (vector), the yellow arrow represents our embedding associated with the JFK quote text, and our less relevant embeddings related to eating sushi are represented with the blue arrows. The black arrows represent any other embeddings we may have present in our knowledge base. As we expected, we see that the embedding corresponding to our JFK text seems to be the most relevant – as it is closer to our input embedding. Similarity scores closer to one indicate a shorter distance between vectors – which implies a more related meaning.
When we add a few more chunks of text and associated embeddings that should be related to the request, we can see that their contextual meaning has been captured and deemed more relevant to the request as well:

At this point, we can return the most relevant pieces of corresponding text to the user. In this simple scenario, if our goal was to return three related pieces of content in order, we would simply rank our matching results and return the quotes from JFK, FDR, and Lincoln in that order.
Conclusion
In summary, embeddings help bridge the gap in understanding between unstructured data and the advanced capabilities of generative AI models. This post explored the concept of embeddings and their role in generative AI and knowledge retrieval. We began by explaining what embeddings are – numerical representations of words, sentences, or entire documents that capture semantic meaning. We highlighted the importance of understanding embeddings, especially for knowledge workers, as they allow generative AI and enterprise search systems to process and retrieve information more effectively.
Through a simple example, we demonstrated how embeddings work by converting text into vectors of numbers and comparing these vectors to measure semantic similarity. This process is important for enabling more accurate and context-aware retrieval of information. The post also touches on the use of distance functions to compare embeddings, focusing on how embeddings can enhance productivity by refining search results and knowledge retrieval.
Learn More About AI for Knowledge Workers
This blog is part of a series on Generative AI concepts and their impact on knowledge workers. To learn more, check out other topics:


