



In this series, we have explored the foundational elements that are driving the transformation of knowledge management through generative AI. We began by examining common patterns like document summarization and knowledge extraction, followed by a deep dive into transformer-based AI models, inference, and their role in processing and generating content. We then looked at embeddings, which help AI understand and retrieve the semantic meaning of unstructured data. And finally, we discussed vector databases which store these embeddings to enable fast and efficient information retrieval. With this post, we will bring these concepts together with the details behind Retrieval Augmented Generation (RAG) – a powerful technique that bridges retrieval and generation to allow AI systems to produce accurate, grounded, context-rich content.
As unstructured data continues to grow exponentially in today’s workplaces, an organization’s ability to efficiently retrieve relevant, up-to-date knowledge and generate contextually relevant insight from AI models can be a challenge. Keyword searches, traditional database queries, or even more manual indexing approaches alone can struggle to meet demands of Generative AI systems charged with producing this specific, relevant insight. At the same time, it is not always practical to train custom AI models to include your most relevant private or corporate data. RAG, which appeared early in the Generative AI revolution as a prominent implementation pattern, has maintained its place as a key part of impactful Generative AI solutions because it can provide a practical bridge between an organization’s unique data and generative AI models.
RAG Stages
At its core, Retrieval Augmented Generation (RAG) is a technique that enhances the capabilities of generative AI models by augmenting the standard prompt / completion flow with two new steps: information retrieval and content generation. While generative models like GPT-4o and o1 are great at many things including generating content and “reasoning”, the models themselves rely on information learned during training and the context provided to them through a user’s prompts to “predict” a suitable response. RAG addresses this limitation by first retrieving relevant, real-time information from knowledge sources external to the model and then including this context in improved prompts to generate more accurate and specific responses. This is a different approach than others you may have heard that address the need to include (and prioritize) domain-specific or confidential data; “fine-tuning” a generative AI model, or fully training a custom model.
RAG operates in two stages. The first stage is retrieval, where the system begins with a user’s prompt, which could be a question or a task request, such as “What are the recent trends in AI in healthcare?” Instead of at once generating a response, the system retrieves information from a knowledge base—this could be internal documents, databases, or external sources such as web pages or research papers. The retrieval step uses techniques like semantic search, powered by embeddings stored in vector databases, to find the most contextually relevant information. The retrieved information provides the grounding context that will be used in the next step
Once the relevant data is retrieved, the system moves to the generation stage. Here, the retrieved information is added to the original prompt to form a new, augmented prompt (or series of prompts). This augmented prompt is then passed to the generative AI model, which uses the retrieved context to create detailed, contextually rich output. In other words, the generative model does not just rely on its training data—it incorporates the fresh, domain-specific context from the retrieval step in its direction to the model to improve the quality of its generated response.
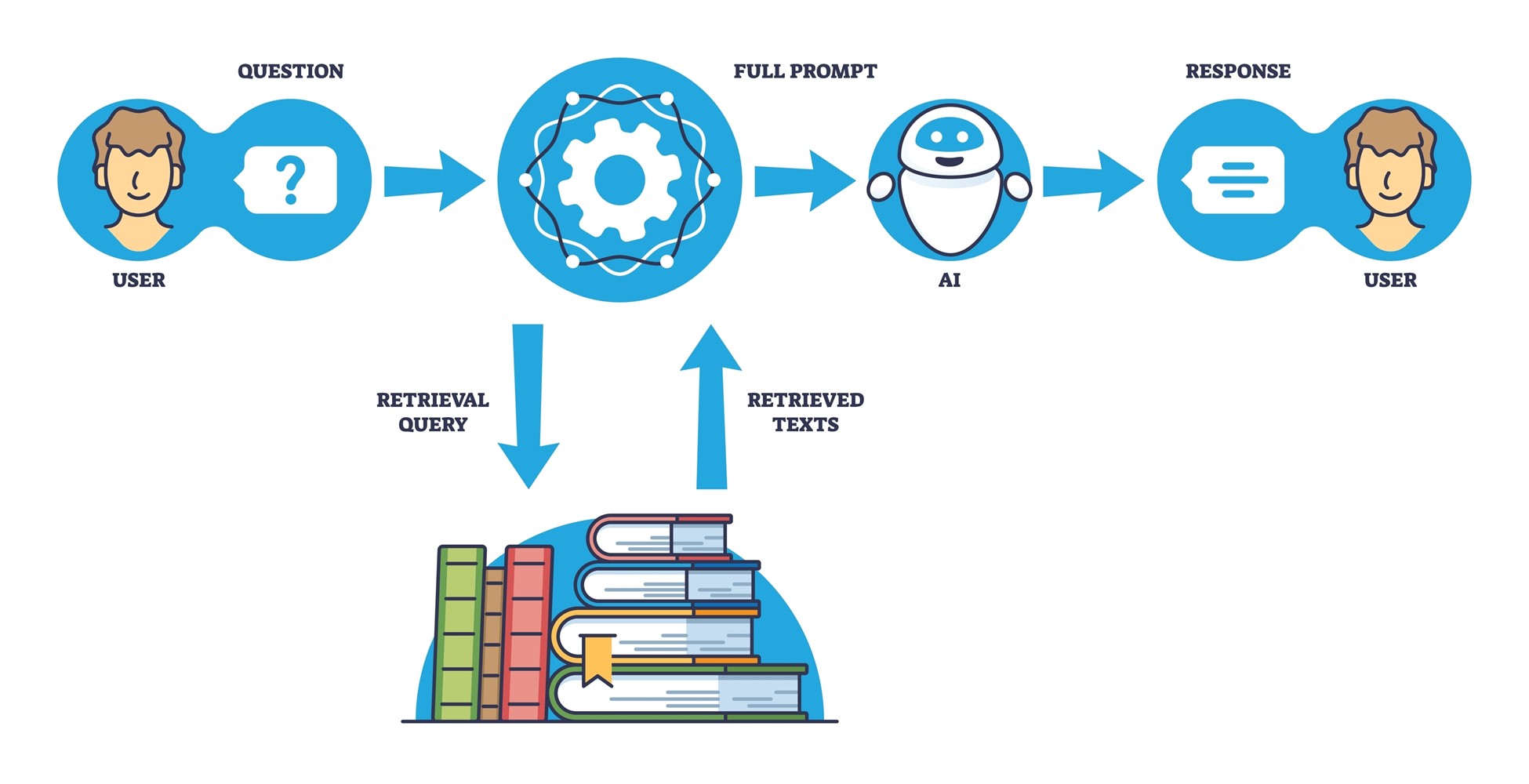
Prompt Augmentation
For a more detailed example, let’s consider a scenario where a knowledge worker at a research firm wants help drafting a report on AI’s impact on healthcare. That worker may start with a simple statement like:
“Please help me create a report on the impact of AI on healthcare.”When submitted to the model, this instruction may render helpful initial results from the model. The response will include information from a broad range of sources and publicly available information. But, unless the model has been trained with this information, it will not include that research firm’s private knowledge, and obviously will not prioritize this content. So, let’s look at how RAG could help improve the results.
Retrieval
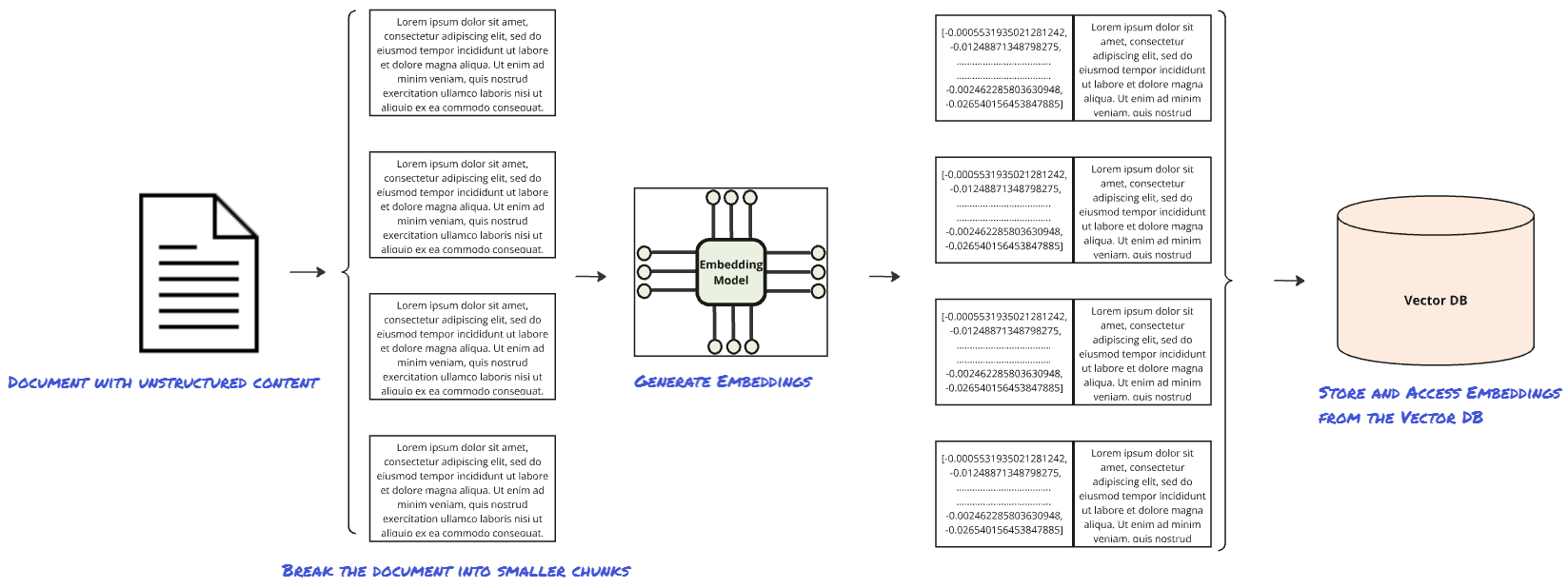
In the first step (retrieval), the system needs to collect related documents from internal databases, research papers, and other relevant sources that discuss AI’s impact on healthcare to ground a response from the model. These documents will have been through initial processing, where:
- Content is split into smaller chunks.
- These chunks of content are converted to vector embeddings that represent the semantic meaning of each chunk.
- The newly created embeddings are stored alongside the original chunks of text (and additional relevant metadata if applicable) in a vector database that is the knowledge store.
As the organization creates new relevant content it is processed on the way in (chunked and embedded) so that the knowledge base is kept up to date.
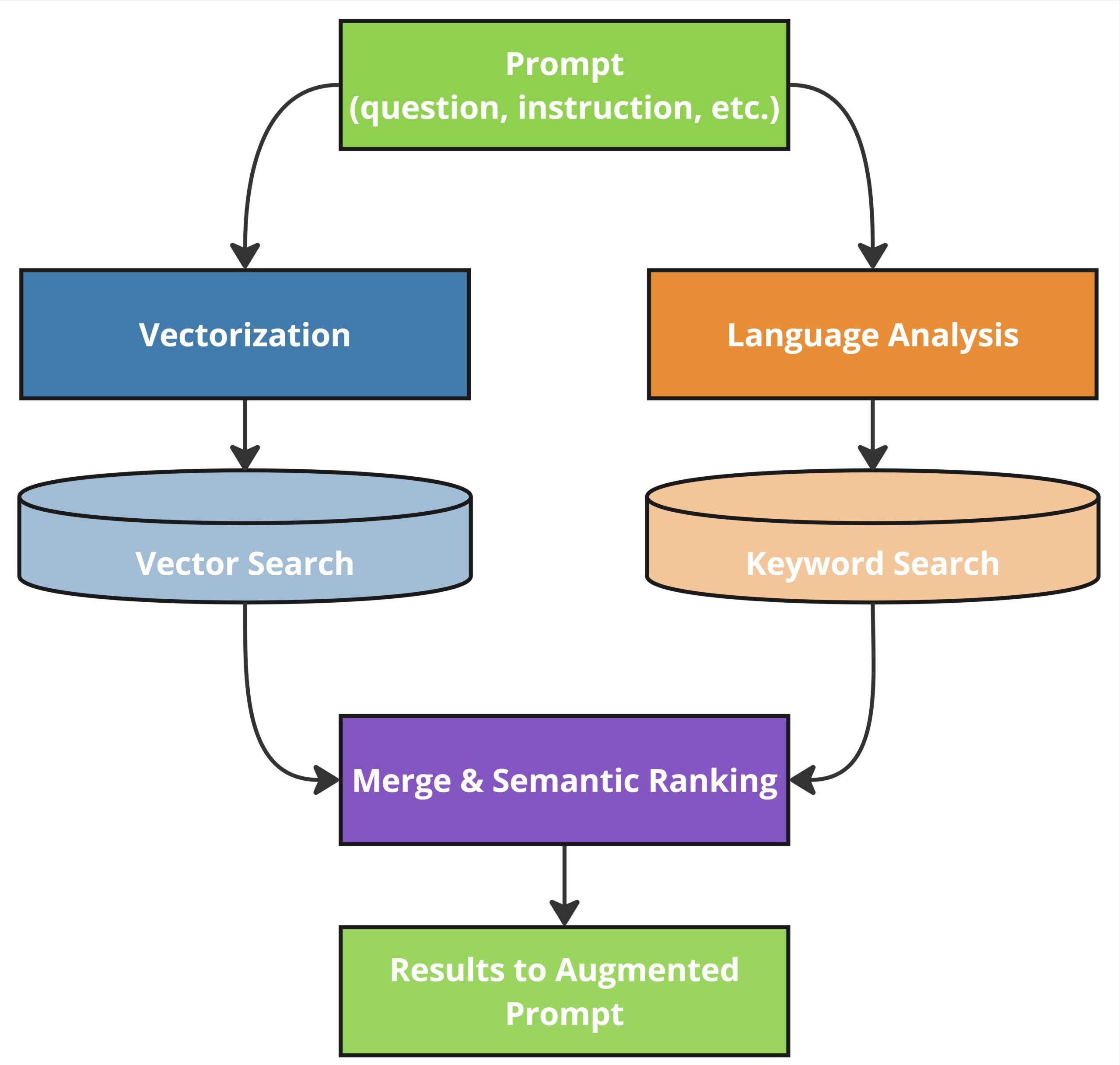
When the user submits the prompt, RAG often starts by converting the instruction itself into an embedding to capture its semantic meaning. This conversion is done on the original prompt so that it is more easily understood and compared against embeddings captured in pre-processing. A search is performed against the knowledge base (which now includes the chunks and associated embeddings).
The returned content is selected based on the semantic similarity to the original instruction. The best method of implementing the semantic search is an evolving topic (and can be dependent on the content), but it generally includes a combination of vector similarity search against the created embeddings, and a keyword search, followed by a ranking algorithm. The retrieved content is then summarized or used directly to augment prompts as input to the generation phase.
Generation
In the second step (generation), the generative AI model takes this augmented prompt and generates a comprehensive, well-informed response. This final output is more accurate and relevant than what would be produced by the generative model alone.
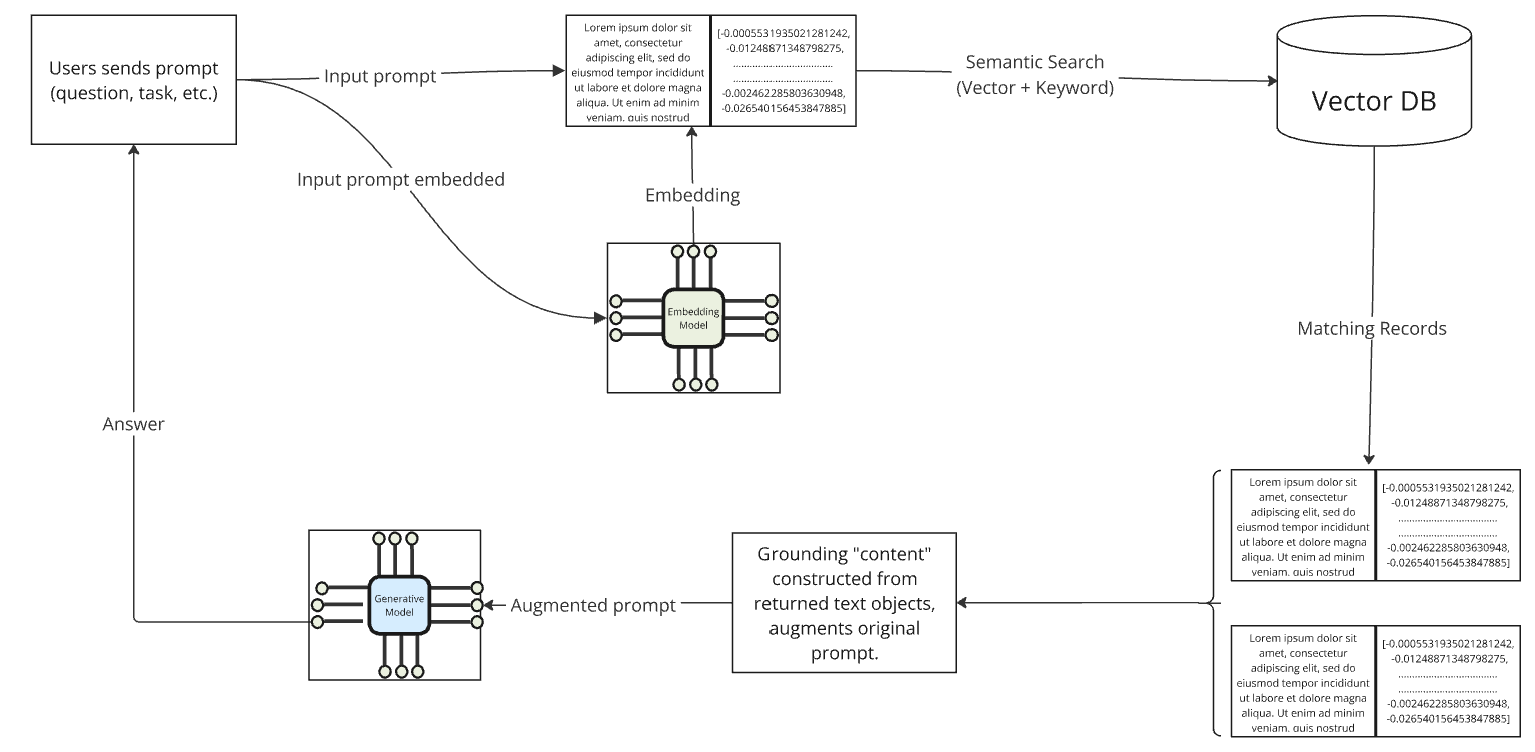
Assuming the process is implemented effectively, what was once a more generic prompt:
“Please help me create a report on the impact of AI on healthcare.”could be enhanced to something like the following example, without requiring the knowledge worker to intervene:

This is a contrived example of an enhanced prompt that would be sent to the model in place of the original, more generic prompt asking for help in building a report to help illustrate the point. Note that the internal systems and documents referenced in the prompt are made up, but the level of detail and internal content references are now present. Hopefully, this example can help you build an intuition for the key points of value RAG presents for knowledge workers:
- RAG improves the accuracy and relevance of generative AI systems in domain-specific scenarios.
- RAG typically runs behind the scenes for knowledge workers as a part of the larger AI system and helps reduce the cognitive load on knowledge workers to provide domain-specific context.
- An effective RAG implementation can stay current with up-to-date internal information more easily by updating the knowledge base.
- RAG can be combined with techniques like model fine-tuning and custom training (it isn’t exclusive) to produce even more relevant results in domain-specific scenarios.
Conclusion
Retrieval Augmented Generation (RAG) represents the culmination of generative AI concepts explored throughout this blog series. It integrates AI-assisted retrieval and generation to address the challenges of handling unstructured data in knowledge work. By automating the retrieval of domain-specific, up-to-date information and using it to generate precise, context-rich outputs, RAG empowers knowledge workers to focus on high-value tasks rather than spending time searching for or synthesizing information. Because it runs behind the scenes for knowledge workers, it reduces the need for complex prompt engineering while improving accuracy and relevance in AI-driven outputs. As organizations continue to adopt generative AI, RAG will continue to play a vital role in making knowledge management systems smarter and more efficient. Now is the time for knowledge workers and organizations alike to explore how RAG can enhance productivity and decision-making.


