






![]() Recently, I encountered an issue with SharePoint 2013 search crawls where .pdf files smaller than 1 MB reported a warning: “The item has been truncated in the index because it exceeds the maximum size”. The default MaxDownLoadSize for documents in SharePoint is 64MB, which was more than enough the handle these relatively small .pdf files.
Recently, I encountered an issue with SharePoint 2013 search crawls where .pdf files smaller than 1 MB reported a warning: “The item has been truncated in the index because it exceeds the maximum size”. The default MaxDownLoadSize for documents in SharePoint is 64MB, which was more than enough the handle these relatively small .pdf files.
After I reached out to some co-workers; one suggested that the error might be a false-positive and the entire document had been crawled. I tested this by first searching for words at the end of the document and no matches were found; this would be expected if it were truncated. Next, I tried searching for text in the middle of the document, no matches were found either. I thought it must have truncated a lot of text and tried searching for text contained at the very beginning of the document. No results were found! So when the warning said it truncated the item, it had truncated the whole document.
I decided to test a Microsoft Word document of approximately the same size and found that it did not throw a warning. I then exported that Word document to .pdf and crawled it and surprisingly no warning was thrown. I took a look at the properties of both .pdf files. I found that problem .pdf file was version 1.3 (Acrobat 4.x) and had been generated by Microsoft SQL Server Reporting Services (SSRS), while my test document was version 1.6 (Acrobat 6.x).
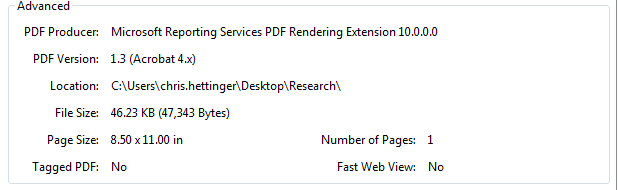
Figure 1. PDF Version 1.3 (Acrobat 4.x) generated by SQL Server Reporting Services (SSRS).
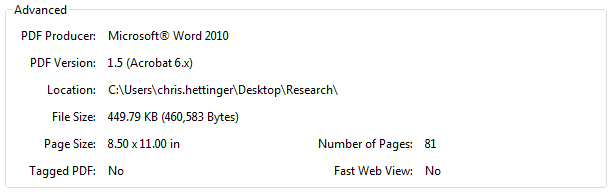
Figure 2. PDF Version 1.5 (Acrobat 6.x) generated by Microsoft Word
This got me thinking that problem was version 1.3, so I converted my .pdf to 1.3 and crawled it. I was surprised to find that it did not throw the warning as I expected it too. This would mean that either 1) the culprit was SSRS report generation (not the version 1.3), or 2) there was something about converting a version 1.5 to a version 1.3 that fixed the issue. With this in mind, I preferred to find a centralized solution rather than converting every .pdf document in our site.
I decided to try using the official Adobe IFilter in place of the one that is built-in to SharePoint 2013. In order to leverage the custom IFilter, I did the following:
- Downloaded & installed the March 2013 PU as it is a prerequisite for the next CU (https://support.microsoft.com/kb/2767999)
- Downloaded & installed the July 2014 CU (https://support.microsoft.com/kb/2767999)
- Downloaded & installed the Adobe IFilter (https://www.adobe.com/support/downloads/detail.jsp?ftpID=5542)
NOTE: May require a reboot - I created the following script based on these instructions for SharePoint 2010
Add-PSSnapin "Microsoft.SharePoint.PowerShell" -ErrorAction SilentlyContinue
$iFilterPath = "C:\Program Files\Adobe\Adobe PDF iFilter 11 for 64-bit platforms\bin\"
$oldPath=(Get-ItemProperty -Path 'Registry::HKEY_LOCAL_MACHINE\System\CurrentControlSet\Control\Session Manager\Environment' -Name PATH).Path
if(!$oldPath.Contains($ifilterPath))
{
Write-Host "Adding Environment Path"
$newPath="$oldPath;$iFilterPath"
Set-ItemProperty -Path 'Registry::HKEY_LOCAL_MACHINE\System\CurrentControlSet\Control\Session Manager\Environment' -Name PATH –Value $newPath
}
Write-Host "Setting Up Registry entries"
#See: https://www.adobe.com/devnet-docs/acrobatetk/tools/AdminGuide/Acrobat_Reader_IFilter_configuration.pdf
$path = "Registry::HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Office Server\15.0\Search\Setup\Filters\.pdf"
if(Test-Path $path) {Remove-Item -Path $path -Recurse}
New-Item $path
New-ItemProperty -Path $path -Name Extension -PropertyType String -Value "pdf"
New-ItemProperty -Path $path -Name FileTypeBucket -PropertyType DWord -Value 1
New-ItemProperty -Path $path -Name MimeTypes -PropertyType String -Value "application/pdf"
$path = "Registry::HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Office Server\15.0\Search\Setup\ContentIndexCommon\Filters\Extension\.pdf"
if(Test-Path $path) {Remove-Item -Path $path -Recurse}
New-Item $path
Remove-Item -Path $path\* -Recurse
New-ItemProperty -Path $path -Name "(Default)" -PropertyType MultiString -Value "{E8978DA6-047F-4E3D-9C78-CDBE46041603}"
$ssa = Get-SPEnterpriseSearchServiceApplication
$filter = Get-SPEnterpriseSearchFileFormat -SearchApplication $ssa -Identity pdf
if(!$filter.UseIFilter)
{
Write-Host "Enabling IFilter for SharePoint"
Set-SPEnterpriseSearchFileFormatState -SearchApplication $ssa -Identity pdf -UseIFilter $true -Enable $true
Write-Host "Restarting Search Service"
$service = Get-SPServiceInstance | ? {$_.TypeName -eq "Search Host Controller Service"}
$service | Stop-SPServiceInstance -Confirm:$false
while(-not (($service | Where-Object {$_.Status -eq "Disabled"}).Count -eq $service.Count)){
write-host -ForegroundColor Yellow $service.Status; sleep 5;
$service = Get-SPServiceInstance | ? {$_.TypeName -eq "Search Host Controller Service"}
}
$service | Start-SPServiceInstance
Write-Host "Restarting IIS"
iisreset
}
After executing the script, I performed a full crawl and was pleased to find that all of the .pdf size-related warnings were gone. I performed a search using the same criteria as before from the end, middle, and beginning of document and this time results were returned.
Conclusion
While I am not certain if the cause of this issue is SSRS document generation or legacy .pdf version 1.3 documents, I was able to solve this issue using the official IFilter from Adobe. If someone else encounters this problem, hopefully this will help.


