



In a previous post, we introduced two basic lifecycle phases in artificial intelligence: training and inference. The article highlighted these two fundamental concepts, differentiating between the act of preparing a model for use (training) and using a model to make predictions (inference).
We also made the point that, typically, knowledge workers interacting with generative AI models would be engaged at the inference stage to interpret content or generate new information. For example, when I ask ChatGPT to summarize content from a document for me or I ask Microsoft Copilot to interpret and provide feedback on an email I am composing, I’m engaged in inference as I’m asking a generative AI model to make a prediction.
This post will go into more depth on generative AI inference, including the following topics:
- The evolution of basic neural networks to the transformer network model, the model that underpins many of today’s advanced generative AI models.
- The basic architecture of transformer-based generative AI models.
- A walkthrough-through of the flow of information that occurs when these models are called on to make a prediction in inference.
Why it’s Important to Understand Inference
Obviously, knowledge workers don’t require a full understanding of the inner workings of generative AI models to use them effectively. This post’s more technical discussion of transformers and inference will leave out a lot of detail about these models’ inner workings. However, we believe it is valuable for anyone using generative AI tools to have a cursory understanding of what happens when a model makes a prediction.
Even a basic understanding can help guide your behavior. For example, it may help you:
- Choose which models to use (do I need to maximize response speed or accuracy?).
- Understand how to shape your prompts for quality results.
- Inform how to best organize your data as you prepare to use generative AI for your specific tasks.
Also, just as investment in training models continues to explode, the industry is demanding more innovation and investment in inference to effectively use these models (Appenzeller, Bornstein, Casado, 2023). As generative AI features are integrated into the software we use every day, we are essentially demanding more from supporting systems after the training phase. Inference will be an important factor in determining the cost, quality, and responsiveness of the generative AI tools that knowledge workers use daily.
From Basic Neural Networks to Transformers
Basic neural network models have influenced the direction of artificial intelligence for decades (Datamapu, 2023). Early models were inspired by the basic structure of the human brain; small, interconnected compute units—“neurons”—are organized into layers and interact with each other to produce a meaningful output. Each neuron is responsible for taking input data, adding “weight” and “bias” adjustments, and running an activation function to produce an output.The output is then passed to neurons in the next layer as input.This process continues until data has propagated through all its layers and an output for the entire model is produced. These early neural network models were able to perform elementary tasks like pattern recognition and classification. Although they were groundbreaking, their capabilities were limited mostly due to their shallow architecture and the constrained computational power of the systems they were trained and run on.
The weight adjustments in this process are a key thing to remember; the weights are numerical values that are assigned to each input, which influence the importance of that input on a neuron’s output. When training a neural network, the weights are first assigned a random value, then adjusted as training progresses and results are evaluated. In inference, the neurons use the trained weights to guide their output. It turns out that the trained weights—you’ll also hear them called “parameters”—are a very important factor in determining the quality of a model’s output.Companies producing today’s leading generative AI models often take great care in securing these weights as proprietary information (Nevo, Lahav, Karpur, Bar-On, Bradley, Alstott, 2024).
As the field of AI progressed, the evolution of deep learning brought new model architectures that offered a broader set of capabilities. Researchers built on the neural network concept of multiple, connected layers of processing to envision and build these models for many different practical use cases. For the purposes of this discussion, you can think of deep learning models as variants of the basic neural network structure, with many more computational layers.
There were a few key enablers from industry that fueled the growth of deep learning:
- It became possible to train these models as computational power continued to double (roughly) every two years. (asml.com, 2022)
- Researchers began using graphical processing units (GPUs) to accelerate training and inference. In 2008 a team of researchers at Stanford, led by Andrew Ng, published a paper describing significant improvements in the training time of a large deep learning model when compared to multi-core CPUs (Ng, Raina, Madhavan, 2008).
- Exponential growth of available data for training these “data-hungry” deep learning models (Rayaprolu, Ivanov, Shahnazari, 2024).
Deep learning models could now efficiently train on much larger data sets and produce increasingly accurate results. These models showed promise across various domains, from image and speech recognition to natural language processing, and they were able to uncover intricate patterns and relationships within data.
Earlier deep learning models set the stage for an even more significant development: the transformer network model. The transformer is a type of deep learning model designed to understand and generate data that is inherently sequential (like text). What makes transformers special is their ability to look at all parts of a sentence at the same time rather than reading it word by word. This helps understand context and makes the transformer faster and more accurate. While originally developed for text-related tasks like language translation and text generation, transformers have proven to be incredibly versatile and are now used in other areas, such as analyzing images, recognizing speech, and even composing music.
Unlike other models that process data sequentially, transformers can train and infer more efficiently through parallelism and a key innovation dubbed “self-attention.” This innovation dramatically improved the efficiency and accuracy of transformer-based AI models, particularly in natural language processing. Transformers were introduced by eight researchers at Google when they published the 2017 paper “Attention is All You Need.” (Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser, Polosukhin, 20217)
Self-attention is a mechanism that allows the model to focus on different parts of an input sequence when making predictions about that sequence. Consider how a human reads a sentence: sometimes, to understand a word better, you need to look at other words in the sentence for context. Self-attention allows the model to look at all words in the sentence at once. This helps in understanding the meaning of each word in the context of the entire sentence, leading to better comprehension. And because self-attention looks at all words simultaneously, it allows for parallel processing, also making the model faster to train and use.
The Transformer Architecture
The core transformer model architecture includes encoder and decoder blocks; and each block is made up of multiple layers. Each layer in the encoder block is functionally identical but is assigned its own set of weights. So, you have multiple encoder layers in the block working together to produce an output that the decoder block (multiple decoder layers) can use as input. The output from the encoder will be a “contextually rich” representation of the original input to the model that the decoder can use to make an accurate prediction.
Similarly, multiple decoder layers work together to produce a predicted sequence using the output from the encoder block. The decoder’s output is then passed through a final output layer, which converts this representation into a usable form (word, pixel, etc.).
Key to both encoder and decoder layers, and a distinguishing feature of the transformer, is the concept we described above: self-attention. Each layer in the encoder and decoder blocks applies self-attention during processing to determine how much importance every token should give to all other tokens (conceptually, think of tokens as individual words). This is how the transformer captures the relationships and dependencies between tokens.
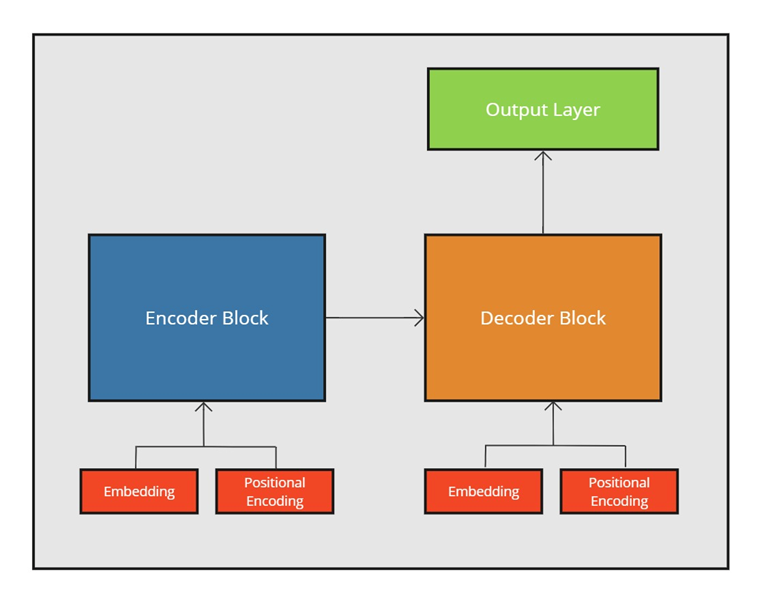
As shown in the diagram above, both the encoder block and the decoder also rely on an embedding and positional encoding layer. This layer creates a vector representation (a list of floating-point numbers you can learn more about in this short video) of the input that the blocks use; the input prompt is used as input to the encoder block, and the iterative prediction sequence is used in the decoder block. These vectors, called embeddings, represent the first step in understanding the meaning of the input for the model to process; the numerical distance between two vectors indicates how related they are. Additionally, positional encodings are added to these embeddings to provide information about the order of the tokens in the sequence, allowing the model to consider the position between tokens for context.
An Overview of Inference Data Flow
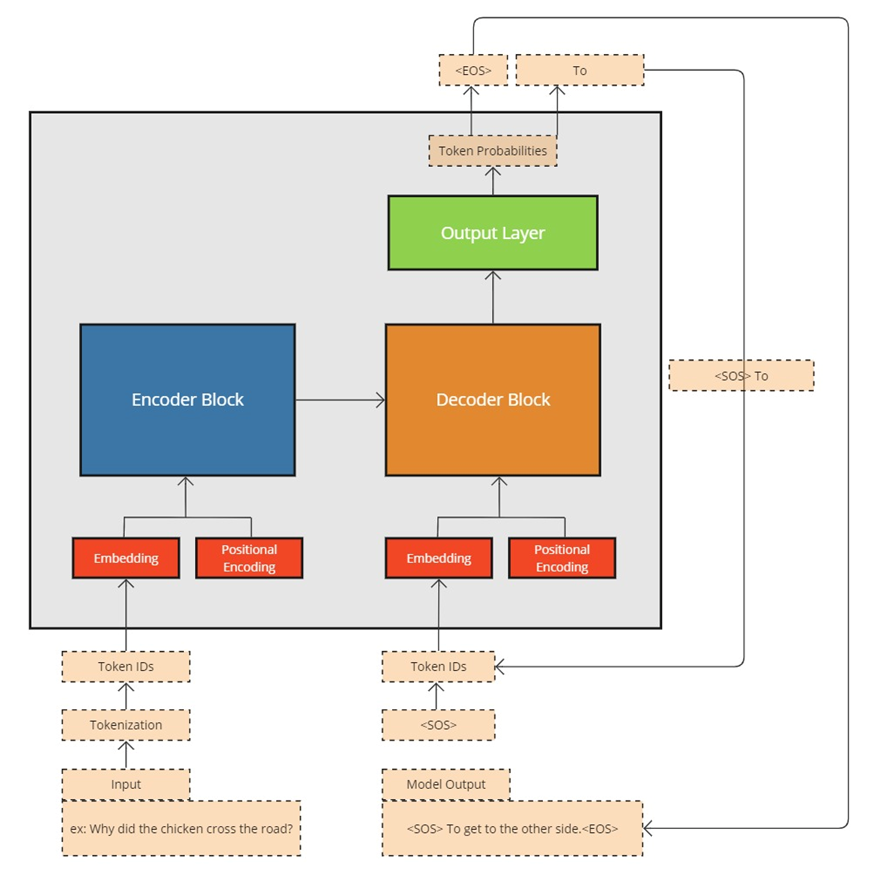
Now that we’ve established the basics of transformer architecture let’s discuss the flow of information when calling the model for inference. In the example above, we send the model a simple query and expect it to return a meaningful answer.
- Input Submission & Tokenization: As a first step, the user input is submitted to the model. In this case, the simple question “Why did the chicken cross the road?” is then split into tokens (words or partial words), and each token is mapped to a numerical ID. Additional information is then applied to the tokens to indicate whether the token should be considered – a real word vs. a blank space, for example. This piece of information is called an “Attention Mask.”
- Embedding: The input is now ready for the model’s embedding layer. The tokens are converted to embeddings, which are simply a list of floating-point numbers.
- Positional Encoding: At this point, information about the token’s position is also applied to the embeddings. This is represented separately in the diagram above in the “Positional Encoding” square. The model must perform this step to retain the correct order of the tokens.
- Encoder: The Encoder layers now work together to generate another sequence of vectors. Once complete, the output from the encoder is now “meaningful”—rich contextual information about in the input sequence is included. Each token’s position and relationship with all other tokens in the sequence is represented.
- Decoder Initiation: The initiation of the decoder block represents the beginning of generation.In inference, Decoding begins with an empty token sequence, save for a special token that indicates the start of a series of tokens that the decoder generates iteratively.This token is often referred to as the “start of sequence” or “SOS” token.
- Generated Sequence Processing: This new input sequence—we’ll call this the generated sequence—follows the same basic process as encoding, only this time the steps are performed on the generated sequence itself. Tokenization, embedding, and positional encoding are applied to prepare the generated sequence. The first time through, the generated sequence only includes the SOS token.
- Decoder: The Decoder layers now work together to process the generated sequence, using the Encoder block’s output and its own finely tuned attention mechanisms.The output from the Decoder block is an encoded sequence of tokens that represent the model’s prediction—we’ll call this the “predicted sequence.”
- Output Layer: The Output layer interprets the predicted sequence and applies probabilities to each token. The output layer then chooses the most likely next token from the predicted sequence and appends it to the end of the generated sequence. In our example above, after the first iteration, the generated sequence includes the original SOS token and the predicted next token: “To.”
- Iterative Decoding: This process continues, token-by-token, until the model ultimately reaches a stopping condition.This happens when it predicts another special token, the “End of Sequence” (EOS) token, or it reaches a pre-set maximum response length. In our example above, the decoding sequence iterated multiple times, predicted the EOS sequence, and exited, producing the result “To get to the other side.”
- Post Processing: Post-processing (not depicted) converts the token sequence to an expected format and returns the result to the user.
Conclusion
Hopefully, this post has provided some insight into transformer-based AI models, how they have impacted the generative AI landscape, an overview of their basic structure, and a sense of what’s happening behind the scenes when we put generative AI tools to use. We stuck to the basics in the architecture and data flow sections and skipped many interesting details. So, for those who are interested, there is so much more to read and learn!
As knowledge workers, we predominantly engage with generative AI during the inference phase, whether it’s for making predictions, generating text, creating images, or other tasks. A fundamental grasp of transformer inference equips us to make better-informed decisions about our interactions with these models, which improves our outcomes. For instance:
- Model Selection: Understanding the trade-offs between different models or model versions enables us to choose the right balance between speed and precision. This is especially crucial for time-sensitive tasks where the timely delivery of results is paramount.
- Prompt Shaping: By shaping our prompts with an awareness of inference mechanisms, we can significantly enhance the relevance and accuracy of the AI-generated knowledge content. This reduces the need for extensive revisions and ensures that the outputs are more aligned with our expectations.
- Data Organization: Thoughtfully organizing our supporting data, and being cognizant of the processing that will occur once it is fed into the model, helps in generating accurate and contextually appropriate results. Proper data categorization and ensuring data quality are examples of potentially helpful steps.
These insights not only streamline our day-to-day use of generative AI as knowledge workers but also maximize its potential to transform our work processes. By leveraging a basic understanding of inference, we can interact with AI more intuitively and effectively.
References and Suggested Resources:
- Appenzeller, Bornstein, Casado. (2023). “Navigating the High Cost of AI Compute.” A16z.com.
- Datamapu. (2023). “A Brief History of Neural Nets”. pub.towardsai.net
- Nevo, Lahav, Karpur, Bar-On, Bradley, Alstott. (2024). “Securing AI Model Weights”. Rand.org
- Ng, Raina, Madhavan. (2008). “Large-scale Deep Unsupervised Learning using Graphics Processors.” robotics.stanford.edu
- Rayaprolu, Ivanov, Shahnazari. (2024). “25+ Impressive Big Data Statistics for 2024”. Techjury.net
- Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser, Polosukhin. (2017). “Attention is All You Need”. arxiv.org
- Doshi. (2020). “Transformers Explained Visually (Part 1): Overview of Functionality”. towardsdatascience.com.
- Furnieles. (2023). “Transformers in-depth – Part 1. Introduction to Transformer models in 5 minutes”. towardsdatascience.com.
- Tech Gumptions. (2023). “Transformer Architecture Simplified”. Medium.com.
- ASML. (2022). The ongoing evolution of Moore’s Law. Asml.com


