



In today’s information-rich workplace, knowledge management is becoming increasingly complex. As organizations create and consume more data than ever before, the task of organizing, storing, and efficiently accessing this information has grown in scope and difficulty. A significant driver of this escalating complexity is the explosion in the volume of unstructured data.
Generative AI is fueling this explosion by allowing anyone to rapidly create text, images, video, or audio by simply issuing natural language prompts. In addition to supplying this content, generative AI models also rely on unstructured data to train, so they are also driving the demand side of this equation. While this content can have great value to organizations, it often doesn’t fit into traditional structured formats like rows and columns.
The scale and nature of this unstructured data have challenged our conventional database systems. It turns out that the strategy of placing large swaths of text, or direct binary representation of files into tables or traditional NoSQL documents is not sufficient to handle the storage and retrieval requirements levied by modern systems (Generative AI systems especially!). How can we efficiently store and access our unstructured data to handle the volume and variety, retrieve it efficiently, and ultimately consider it core organizational knowledge?
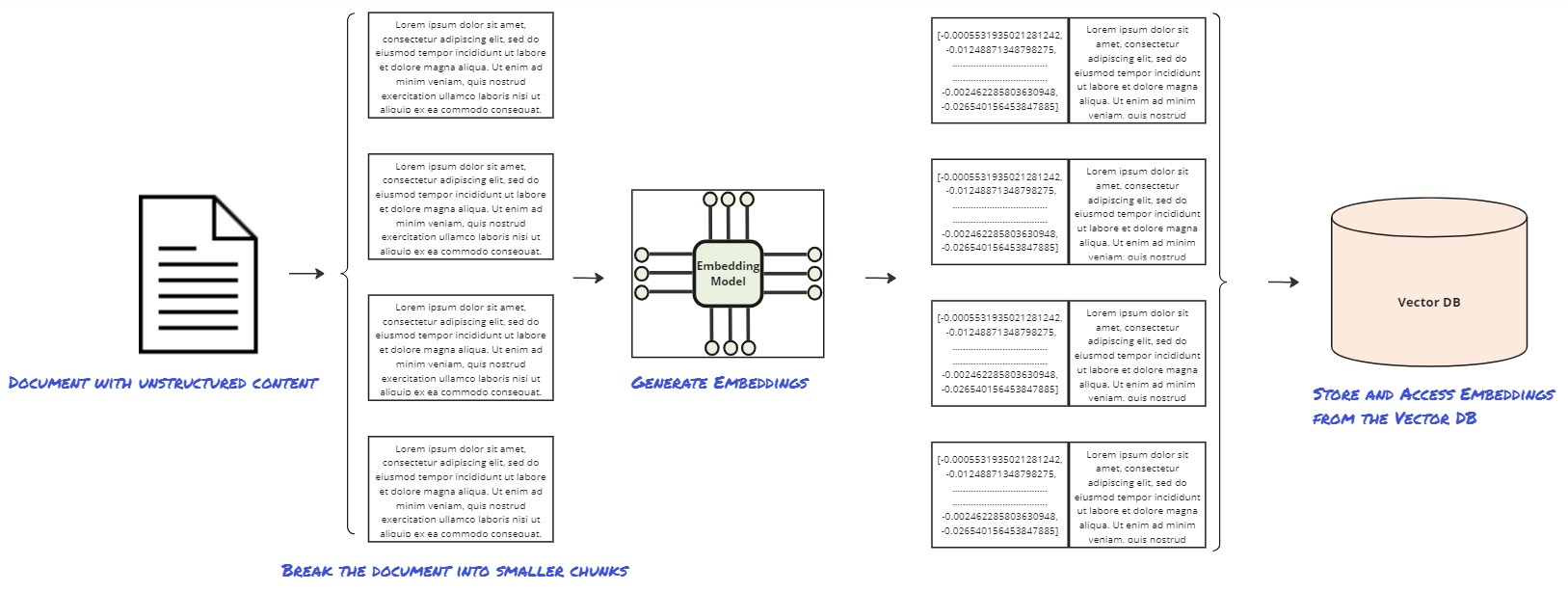
An important pattern has emerged that offers promise. At its core, the pattern involves breaking our content into chunks, capturing the semantic meaning of these chunks as numeric vectors (embeddings), and storing these vectors in a specific kind of database system optimized to handle vector storage and retrieval. The original content itself (or pointers to it) is stored alongside the vector for rapid recall.
- Break unstructured content into chunks.
- Capture the semantic meaning as embeddings.
- Store and access the embeddings from a Vector Database.
- Efficiently “query” embedding vectors on demand.
Background
Though not necessarily “easy,” storing and issuing queries against structured data to extract meaningful insights is not particularly complex at this point. For years, we’ve faithfully relied on our Relational and NoSQL database systems to anchor our applications. More recently, however, the scale and nature of this unstructured data have challenged these conventional database systems.
Relational Databases
- Schema Rigidity: Relational databases rely on a predefined schema, meaning all data must conform to a specific structure (tables, rows, columns). Unstructured data, by nature, doesn’t fit easily into this rigid format, making it difficult to store or requiring extensive preprocessing to normalize the data. In addition, as unstructured data evolves (e.g., new types of data, changes in data format), relational databases struggle with flexibility. Changing the schema to accommodate new data types can be cumbersome, time-consuming, and prone to errors.
- Inefficient Querying: Querying unstructured data, such as searching text within documents or extracting meaning from media files, is inefficient in relational databases. They are optimized for structured data and struggle with full-text searches or pattern matching across large, unstructured datasets. While relational databases can handle large amounts of structured data, they do not scale as efficiently when dealing with unstructured data. The performance of queries degrades as the volume of unstructured data grows.
- Normalization and Indexing: Storing unstructured data often requires creating complex indexes or breaking the data into structured components (e.g., text fields, metadata). This can lead to significant overhead manual work and maintenance.
Traditional NoSQL Databases
- Lack of Advanced Query Capabilities: While traditional NoSQL databases are more flexible in handling unstructured data (e.g., documents, key-value pairs), they often lack the sophisticated query capabilities to perform complex searches and analysis. For example, querying within nested documents or performing full-text searches across large datasets can be challenging. Traditional NoSQL databases are typically designed for simple read and write operations rather than complex analytical queries. This limitation makes it difficult to extract insights from unstructured data without additional processing or external tools.
- Consistency and Data Integrity: Many traditional NoSQL databases, especially those optimized for distributed environments, operate on an eventual consistency model rather than strong consistency. This can lead to challenges when ensuring the accuracy and integrity of queries across large datasets of unstructured information. Ensuring the integrity and consistency of unstructured data across different nodes or clusters in a traditional NoSQL environment can be problematic, particularly when dealing with large, distributed datasets.
Vector Databases
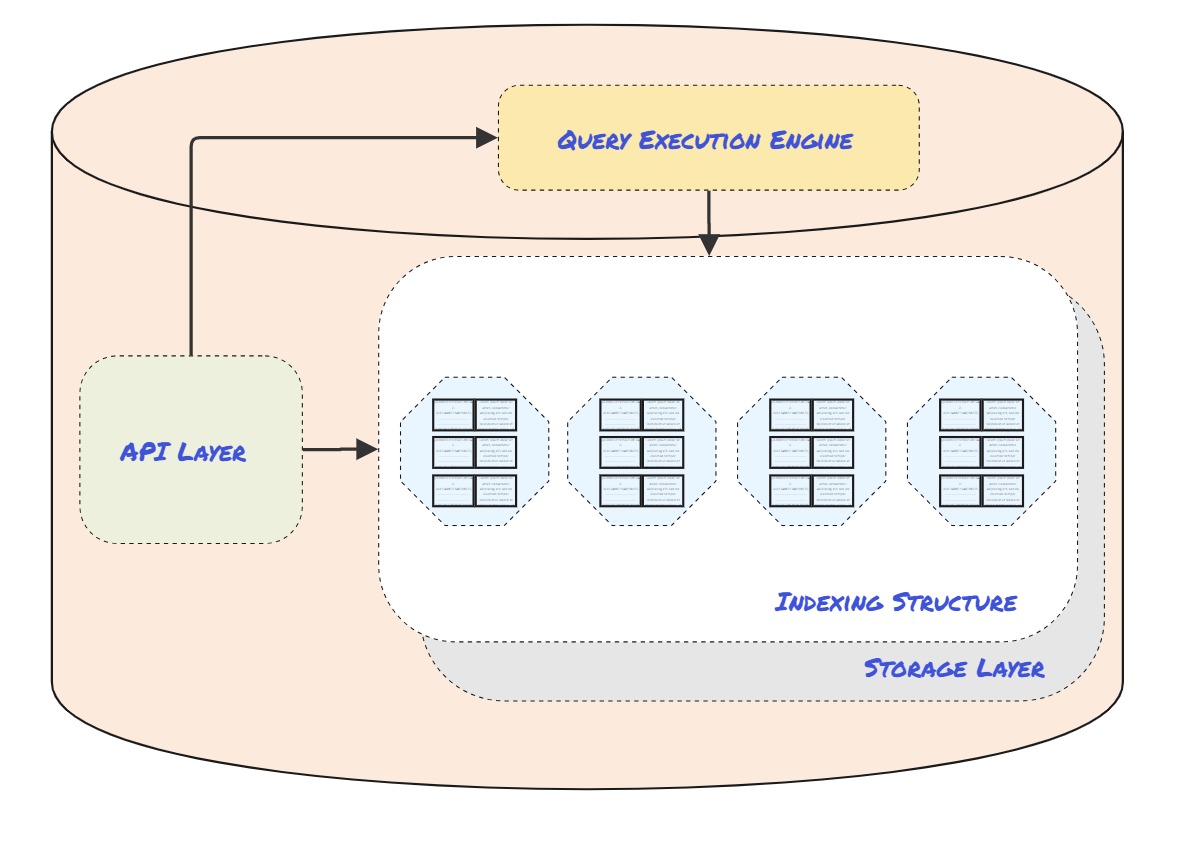
Vector databases have gained momentum because they can address these challenges. Again, the key value proposition for these systems is their ability to efficiently store, manage, and retrieve unstructured data using the pattern we laid out above. Let’s examine the core components of the vector database to help understand how they help address these challenges.
Indexing Structure: Vector databases are designed to find similar vectors to an incoming query vector quickly. The indexing structure is responsible for organizing and partitioning the vector space in a way that allows for fast retrieval, even in large datasets, by rapidly narrowing down the search space. Most current vector databases use at least one of a class of algorithms called Approximate Nearest Neighbor (ANN) as the underlying method for narrowing the search space and retrieving vectors efficiently. The indexing structure is often considered the “core” element of the vector database.
Storage Layer: As the vector embedding is the fundamental unit stored, the storage layer is optimized for the specific needs of vectors. The storage layer includes mechanisms to handle the sparse and dense nature of vector data and helps balance the trade-off between storage space and retrieval speed. To handle inevitably large datasets, vector databases often distribute data across multiple nodes through sharding or partitioning. Sharding or partitioning is often done based on vector similarity, where similar vectors are stored together to reduce cross-node search times. Additionally, the storage engine often provides features such as replication to ensure high availability, fault tolerance, and durability.
Query Execution Engine: This component processes search queries by leveraging the vector indexes to minimize the number of comparisons needed. It is integrated with the storage layer and relies on the databases’ ANN implementation to return results. The execution engine also supports various required operations like filtering, ranking, and aggregating results directly.
API Layer: The API Layer is the interface through which external applications and users interact with the vector database. Typically, the API layer provides three primary functions:
- Data Ingestion: The API layer provides the endpoints for inserting, updating, and deleting vectors in the database. This includes adding new vector embeddings generated by machine learning models, updating existing vectors, or removing obsolete vectors
- Query Execution: The API layer allows users to perform similarity searches by submitting query vectors.
- Index Management: Applications and users can interact with the indexing structure through the API to create, updating, or delete indexes. The API might also provide endpoints for monitoring the status of indexes and managing the indexing process (e.g., reindexing data after a bulk update).
Limitations and Considerations
- Exact Keyword Matching: The primary focus of vector databases is on finding similar vectors based on numerical proximity rather than on exact text matches, so in cases where matching an exact term is important, a vector similarity search in a vector database in isolation isn’t always the best solution. This can lead to scenarios where exact phrases or terms crucial to the query are overlooked in favor of semantically similar but not identical results. To mitigate this limitation, hybrid approaches can be employed, combining vector-based search with traditional keyword-based search methods. This approach combines filtering results using keyword matches and then applying vector-based similarity scoring (which combines exact matches with semantic relevance).
- Sequence Length Constraints: The data being stored and queried must fit within the maximum sequence length of the embedding model used, which can restrict the ability to fully capture the context or details of longer texts or complex data. This constraint may lead to the loss of information if the content exceeds the model’s capacity, which can result in embeddings that do not accurately represent the entire input. This constraint is more about the embedding model chosen than the actual vector database, but it is a constraint worth considering when working with stored embeddings. To mitigate this limitation, the most common approach is to divide the unstructured content into smaller chunks that fit within the model’s sequence length, embed these chunks, and store them separately in the Vector DB (as discussed in the pattern above).
- Approximation Trade-Offs: As we discussed in the description of the indexing structure and query execution engine, most current vector databases typically use one or more ANN algorithms to determine which results are “similar enough” to return. Approximate nearest neighbor (ANN) algorithms prioritize faster retrieval times at the expense of occasionally returning results that are not the exact nearest neighbors. This trade-off can lead to less precise results, which may not be acceptable in applications that require precision accuracy. IIn some cases, the algorithm itself can be fine-tuned to meet the application’s specific need as a mitigation strategy. A more common approach, however, is to add a verification step where the approximate results are filtered by more exact criteria.
- Security Features: Though vector databases have been available for some time, the need to manage and query high-dimensional vector data has become more pronounced as generative AI has gone mainstream (~2022). With this rise, new entrants have entered the market and met many of the core requirements needed to manage unstructured data as high dimensional numeric data. However, these systems often lack supporting features traditional database systems have established long ago. One of the most obvious of these we’ve noticed is out-of-box security features, which allow us to avoid implementing complex, potentially brittle solutions at the application layer. A good example of this is row-level security. Most all traditional database vendors have features that allow security policies to restrict access to specific data points based on user roles or permissions. Many of the newer, purpose-built vector database vendors are still developing these features, so adoption requires thinking through your adoption very carefully if your use case calls for tight control.
Current State and Examples
Vector database functionality available in the market today currently exists in two core categories of offerings; purpose-built vector databases and traditional databases that have added vector search capabilities.
Purpose-built vector databases
These systems have been designed from the beginning to manage, store, and retrieve vector data. Advantages of these systems include:
- Optimized Performance: Purpose-built vector databases often offer faster and more accurate pure similarity searches compared to traditional databases with vector capabilities.
- Scalability: These databases are engineered to scale with the demands of large-scale AI and machine learning applications, enabling them to manage billions of vectors across distributed systems without significant performance degradation. Part of this equation is the fact that the overhead incurred in providing “enterprise” features is avoided.
- Advanced Tuning: Support for multiple indexing methods, choice in algorithms, etc.
A few examples of current market leaders:
Traditional Databases + Vector Search
The second category includes vector database features added to existing database systems, where traditional databases have integrated vector storage and search capabilities into their platforms. The advantages in adopting these databases for vector storage and search capabilities include:
- Ease of Adoption: Adding vector search capabilities to a familiar database system reduces the learning curve and complexity for teams that are already using the database, allowing for faster implementation and integration into existing workflows.
- Cost Considerations: Since these features are added to existing database systems, organizations can leverage their current infrastructure without the need to invest in new, specialized systems, potentially lowering the total cost of ownership.
- Enterprise Management Features: These systems may still have an advantage related to support for existing enterprise database features because they can leverage a mature ecosystem of tools and features that enterprises already rely on. These databases often come with robust features such as transaction management, security (including role-based access control), backup and recovery, and data consistency mechanisms that are essential for enterprise applications.
Here are a few examples of “traditional” database systems that have added vector search capabilities:
Conclusion
Vector databases represent an important innovation that addresses the challenge of efficient storage and retrieval of unstructured data. As organizations continue to generate vast amounts of unstructured content, the ability of vector databases to semantically index and rapidly retrieve relevant information will become increasingly critical. The dual landscape of purpose-built vector databases and enhanced traditional systems provides flexibility for enterprises to choose solutions that best fit their needs.
Understanding and leveraging vector databases (even if indirectly through applications) is also important for individuals engaged in knowledge work. These databases empower knowledge workers to access relevant information quickly and accurately from massive and complex datasets, enabling them to make better decisions, drive innovation, and maintain a competitive edge. As the reliance on unstructured data continues to grow, the ability to efficiently prepare, manage, and retrieve this information will be a key skill. Looking forward, the impact of vector databases on knowledge work is poised to enable more intelligent data management, faster decision-making, and more insightful analysis. As this technology matures, it will play a pivotal role in how organizations manage their knowledge assets, making previously unmanageable data a key driver of innovation and competitive advantage.
Learn More About AI for Knowledge Workers
This blog is part of a series on Generative AI concepts and their impact on knowledge workers. To learn more, check out other topics:
- Embeddings in Action: How AI Understands & Retrieves Knowledge
- Transformer-Based AI Models: Overview, Inference & the Impact on Knowledge Work
- 15 Common Patterns & Concepts on Generative AI for Knowledge Management
References and Suggested Resources
- Rao. (2023). “Vector databases (2): Understanding their internals”. thedataquarry.com.
- Malhotra. “Unlocking the Power of Vector Databases: A Comprehensive Guide (Real-World Examples)”. scalablepath.com
- Soni. (2023). “Why are vector databases now a hot topic?” linkedin.com.
- Forrester. (2024). “Vector Databases Are Critical For AI Strategy”. forbes.com.
- Liu. (2024). “Emerging Trends in Vector Database Research and Development”. zilliz.com.
- Pal. (2023). “The Why, What, Who and Where of Vector Databases”. eckerson.com.
- Ip. (2023). “Why we replaced Pinecone with PGVector”. medium.com
- Elastic Platform Team. (2024). “Understanding the approximate nearest neighbor (ANN) algorithm”. elastic.co
- Kumar. (2023). “The Ultimate Guide to the Vector Database Landscape: 2024 and Beyond”. singlestore.com


